 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Theory of Local Learning, the Learning Channel, and the Optimality of Backpropagation
Paper and Code
Oct 21, 2016
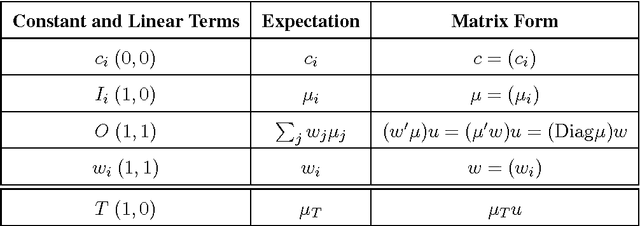
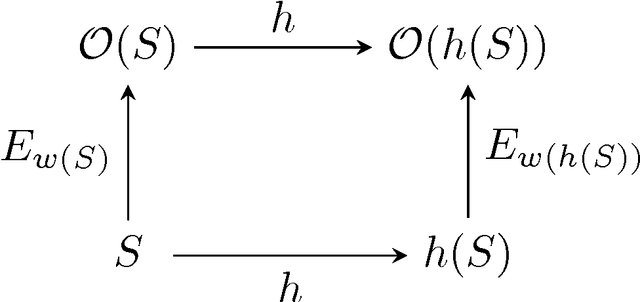
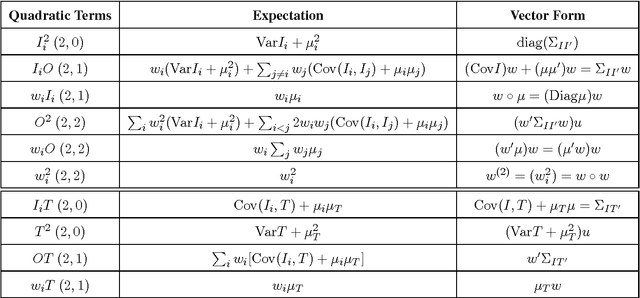
In a physical neural system, where storage and processing are intimately intertwined, the rules for adjusting the synaptic weights can only depend on variables that are available locally, such as the activity of the pre- and post-synaptic neurons, resulting in local learning rules. A systematic framework for studying the space of local learning rules is obtained by first specifying the nature of the local variables, and then the functional form that ties them together into each learning rule. Such a framework enables also the systematic discovery of new learning rules and exploration of relationships between learning rules and group symmetries. We study polynomial local learning rules stratified by their degree and analyze their behavior and capabilities in both linear and non-linear units and networks. Stacking local learning rules in deep feedforward networks leads to deep local learning. While deep local learning can learn interesting representations, it cannot learn complex input-output functions, even when targets are available for the top layer. Learning complex input-output functions requires local deep learning where target information is communicated to the deep layers through a backward learning channel. The nature of the communicated information about the targets and the structure of the learning channel partition the space of learning algorithms. We estimate the learning channel capacity associated with several algorithms and show that backpropagation outperforms them by simultaneously maximizing the information rate and minimizing the computational cost, even in recurrent networks. The theory clarifies the concept of Hebbian learning, establishes the power and limitations of local learning rules, introduces the learning channel which enables a formal analysis of the optimality of backpropagation, and explains the sparsity of the space of learning rules discovered so far.