 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy
Paper and Code
Jun 15, 2015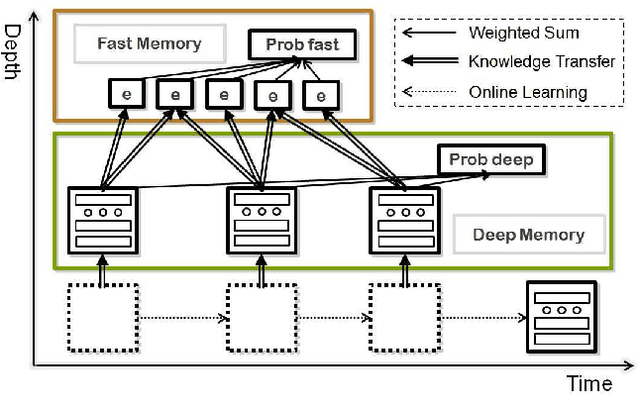
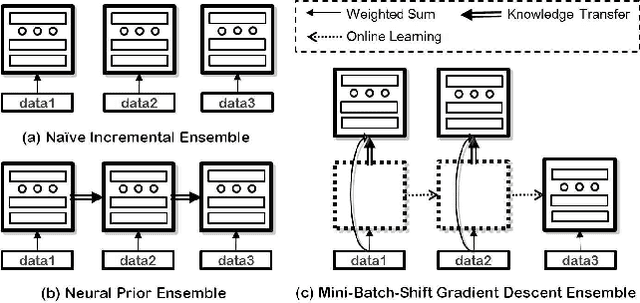
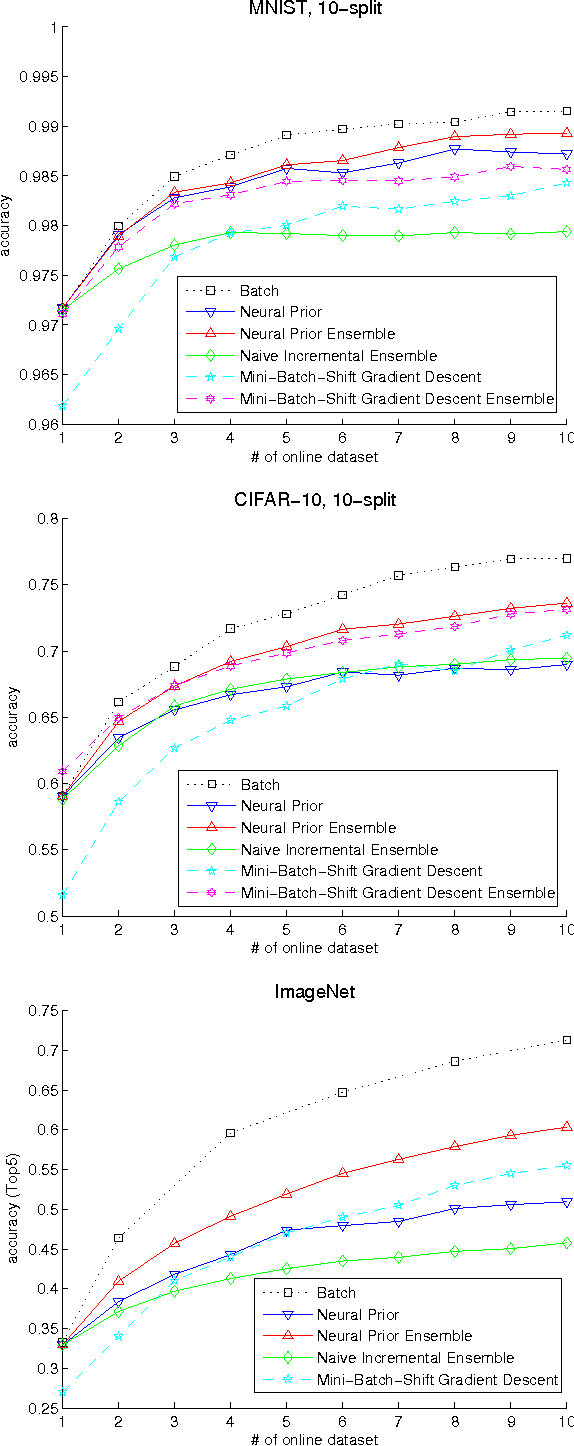
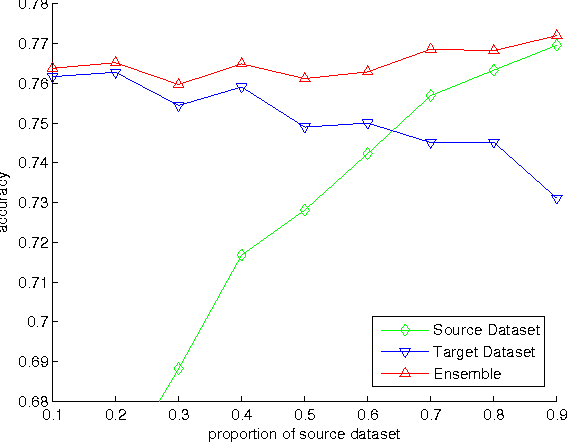
The online learning of deep neural networks is an interesting problem of machine learning because, for example, major IT companies want to manage the information of the massive data uploaded on the web daily, and this technology can contribute to the next generation of lifelong learning. We aim to train deep models from new data that consists of new classes, distributions, and tasks at minimal computational cost, which we call online deep learning. Unfortunately, deep neural network learning through classical online and incremental methods does not work well in both theory and practice. In this paper, we introduce dual memory architectures for online incremental deep learning. The proposed architecture consists of deep representation learners and fast learnable shallow kernel networks, both of which synergize to track the information of new data. During the training phase, we use various online, incremental ensemble, and transfer learning techniques in order to achieve lower error of the architecture. On the MNIST, CIFAR-10, and ImageNet image recognition tasks, the proposed dual memory architectures performs much better than the classical online and incremental ensemble algorithm, and their accuracies are similar to that of the batch learner.