 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Word Embeddings for Spoken Document Summarization
Paper and Code
Jun 14, 2015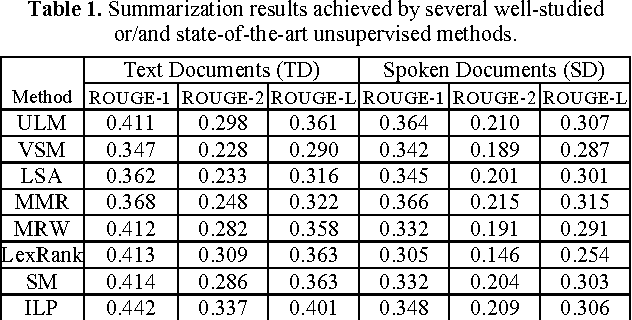
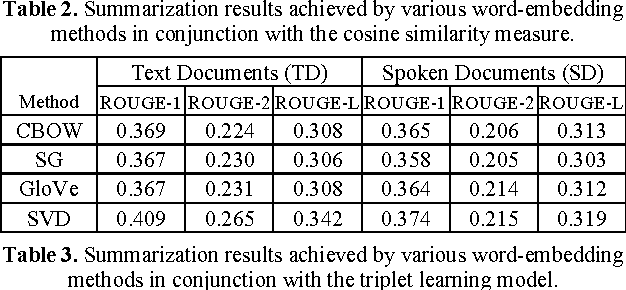
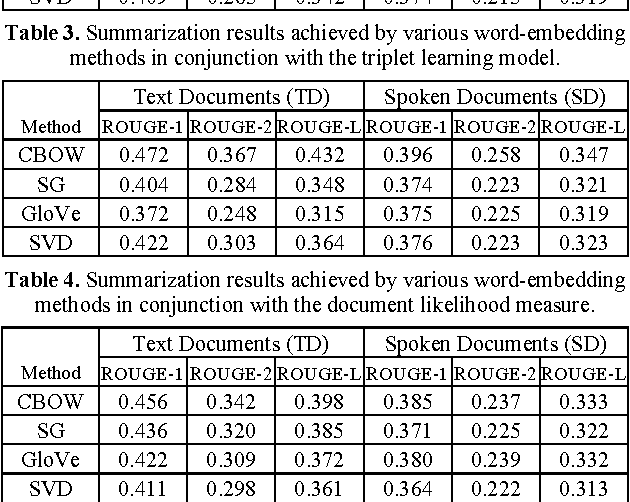
Owing to the rapidly growing multimedia content available on the Internet, extractive spoken document summarization, with the purpose of automatically selecting a set of representative sentences from a spoken document to concisely express the most important theme of the document, has been an active area of research and experimentation. On the other hand, word embedding has emerged as a newly favorite research subject because of its excellent performance in many natural language processing (NLP)-related tasks. However, as far as we are aware, there are relatively few studies investigating its use in extractive text or speech summarization. A common thread of leveraging word embeddings in the summarization process is to represent the document (or sentence) by averaging the word embeddings of the words occurring in the document (or sentence). Then, intuitively, the cosine similarity measure can be employed to determine the relevance degree between a pair of representations. Beyond the continued efforts made to improve the representation of words, this paper focuses on building novel and efficient ranking models based on the general word embedding methods for extractive speech summarization. Experimental results demonstrate the effectiveness of our proposed methods, compared to existing state-of-the-art methods.