 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Fine Tuning for Word Embedding with Integrated Knowledge
Paper and Code
May 29, 2015
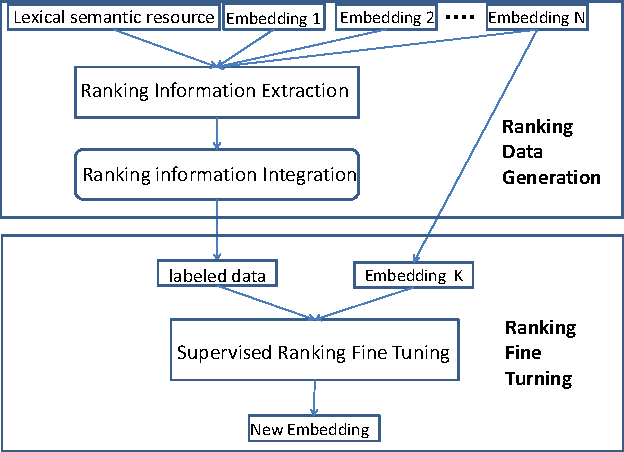

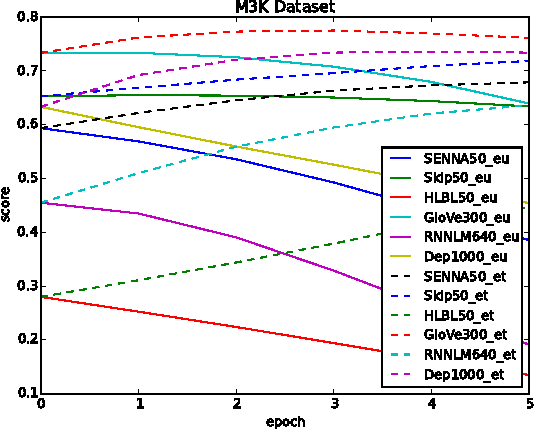
Learning vector representation for words is an important research field which may benefit many natural language processing tasks. Two limitations exist in nearly all available models, which are the bias caused by the context definition and the lack of knowledge utilization. They are difficult to tackle because these algorithms are essentially unsupervised learning approaches. Inspired by deep learning, the authors propose a supervised framework for learning vector representation of words to provide additional supervised fine tuning after unsupervised learning. The framework is knowledge rich approacher and compatible with any numerical vectors word representation. The authors perform both intrinsic evaluation like attributional and relational similarity prediction and extrinsic evaluations like the sentence completion and sentiment analysis. Experiments results on 6 embeddings and 4 tasks with 10 datasets show that the proposed fine tuning framework may significantly improve the quality of the vector representation of words.