 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel selection of polynomial kernel regression
Paper and Code
Mar 07, 2015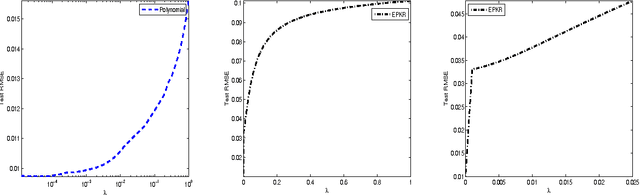
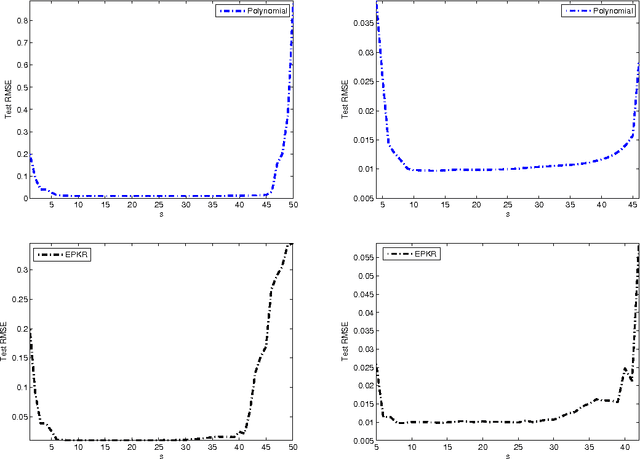
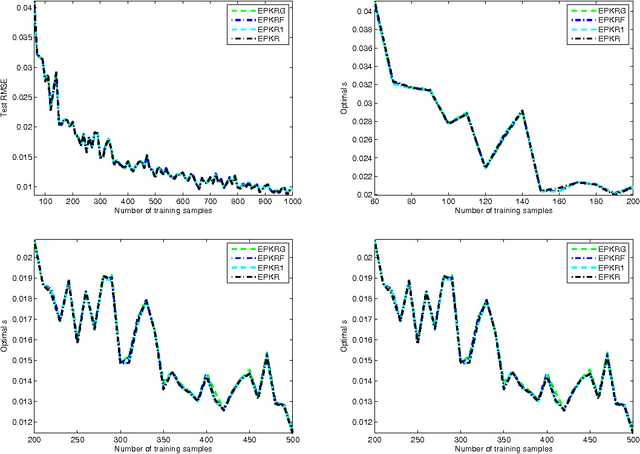
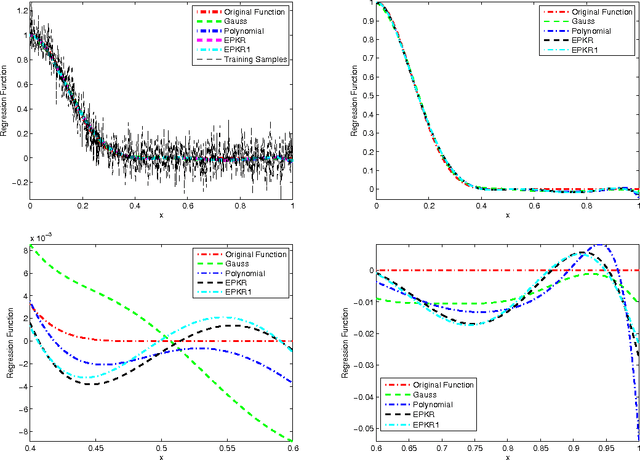
Polynomial kernel regression is one of the standard and state-of-the-art learning strategies. However, as is well known, the choices of the degree of polynomial kernel and the regularization parameter are still open in the realm of model selection. The first aim of this paper is to develop a strategy to select these parameters. On one hand, based on the worst-case learning rate analysis, we show that the regularization term in polynomial kernel regression is not necessary. In other words, the regularization parameter can decrease arbitrarily fast when the degree of the polynomial kernel is suitable tuned. On the other hand,taking account of the implementation of the algorithm, the regularization term is required. Summarily, the effect of the regularization term in polynomial kernel regression is only to circumvent the " ill-condition" of the kernel matrix. Based on this, the second purpose of this paper is to propose a new model selection strategy, and then design an efficient learning algorithm. Both theoretical and experimental analysis show that the new strategy outperforms the previous one. Theoretically, we prove that the new learning strategy is almost optimal if the regression function is smooth. Experimentally, it is shown that the new strategy can significantly reduce the computational burden without loss of generalization capability.