 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtility-Theoretic Ranking for Semi-Automated Text Classification
Paper and Code
Mar 02, 2015
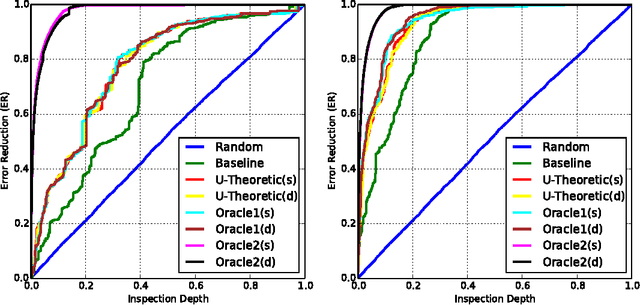
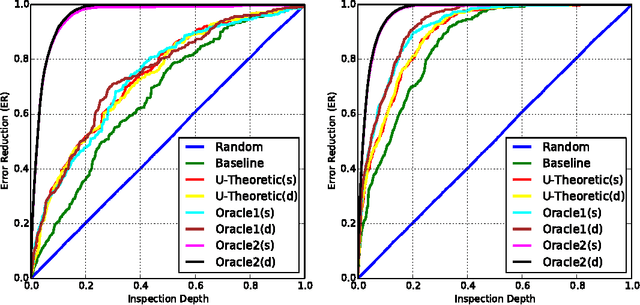
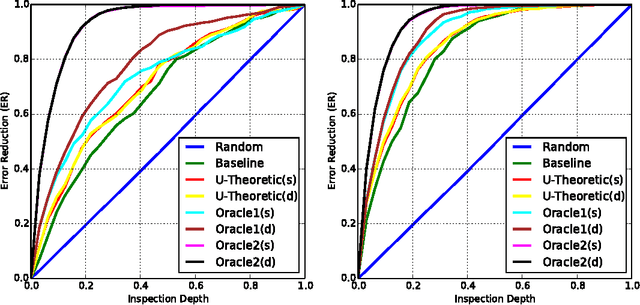
\emph{Semi-Automated Text Classification} (SATC) may be defined as the task of ranking a set $\mathcal{D}$ of automatically labelled textual documents in such a way that, if a human annotator validates (i.e., inspects and corrects where appropriate) the documents in a top-ranked portion of $\mathcal{D}$ with the goal of increasing the overall labelling accuracy of $\mathcal{D}$, the expected increase is maximized. An obvious SATC strategy is to rank $\mathcal{D}$ so that the documents that the classifier has labelled with the lowest confidence are top-ranked. In this work we show that this strategy is suboptimal. We develop new utility-theoretic ranking methods based on the notion of \emph{validation gain}, defined as the improvement in classification effectiveness that would derive by validating a given automatically labelled document. We also propose a new effectiveness measure for SATC-oriented ranking methods, based on the expected reduction in classification error brought about by partially validating a list generated by a given ranking method. We report the results of experiments showing that, with respect to the baseline method above, and according to the proposed measure, our utility-theoretic ranking methods can achieve substantially higher expected reductions in classification error.