 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeclarative Statistical Modeling with Datalog
Paper and Code
Jan 05, 2015

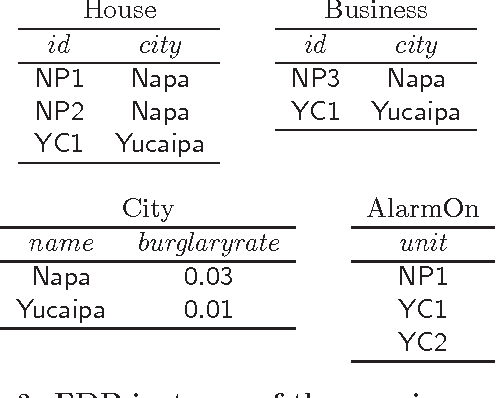
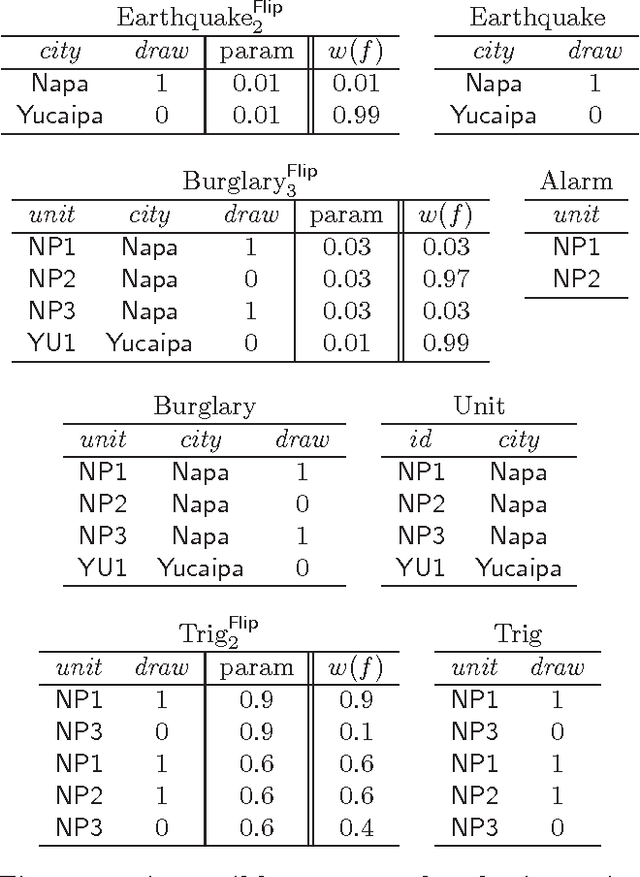
Formalisms for specifying statistical models, such as probabilistic-programming languages, typically consist of two components: a specification of a stochastic process (the prior), and a specification of observations that restrict the probability space to a conditional subspace (the posterior). Use cases of such formalisms include the development of algorithms in machine learning and artificial intelligence. We propose and investigate a declarative framework for specifying statistical models on top of a database, through an appropriate extension of Datalog. By virtue of extending Datalog, our framework offers a natural integration with the database, and has a robust declarative semantics. Our Datalog extension provides convenient mechanisms to include numerical probability functions; in particular, conclusions of rules may contain values drawn from such functions. The semantics of a program is a probability distribution over the possible outcomes of the input database with respect to the program; these outcomes are minimal solutions with respect to a related program with existentially quantified variables in conclusions. Observations are naturally incorporated by means of integrity constraints over the extensional and intensional relations. We focus on programs that use discrete numerical distributions, but even then the space of possible outcomes may be uncountable (as a solution can be infinite). We define a probability measure over possible outcomes by applying the known concept of cylinder sets to a probabilistic chase procedure. We show that the resulting semantics is robust under different chases. We also identify conditions guaranteeing that all possible outcomes are finite (and then the probability space is discrete). We argue that the framework we propose retains the purely declarative nature of Datalog, and allows for natural specifications of statistical models.