 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Random Field Autoencoders for Unsupervised Structured Prediction
Paper and Code

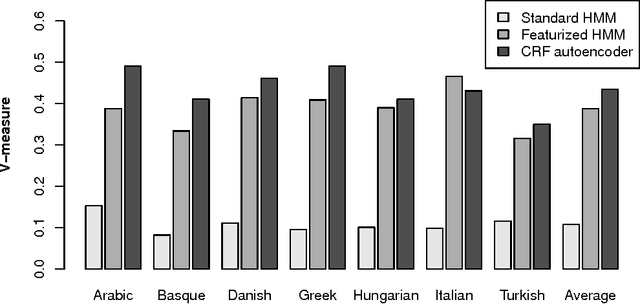
We introduce a framework for unsupervised learning of structured predictors with overlapping, global features. Each input's latent representation is predicted conditional on the observable data using a feature-rich conditional random field. Then a reconstruction of the input is (re)generated, conditional on the latent structure, using models for which maximum likelihood estimation has a closed-form. Our autoencoder formulation enables efficient learning without making unrealistic independence assumptions or restricting the kinds of features that can be used. We illustrate insightful connections to traditional autoencoders, posterior regularization and multi-view learning. We show competitive results with instantiations of the model for two canonical NLP tasks: part-of-speech induction and bitext word alignment, and show that training our model can be substantially more efficient than comparable feature-rich baselines.