 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgecuDNN: Efficient Primitives for Deep Learning
Paper and Code
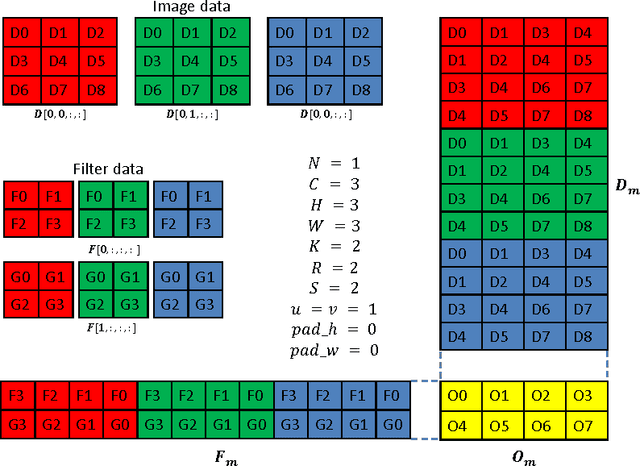
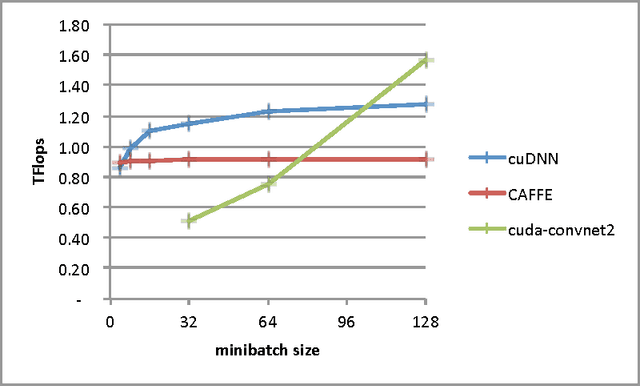
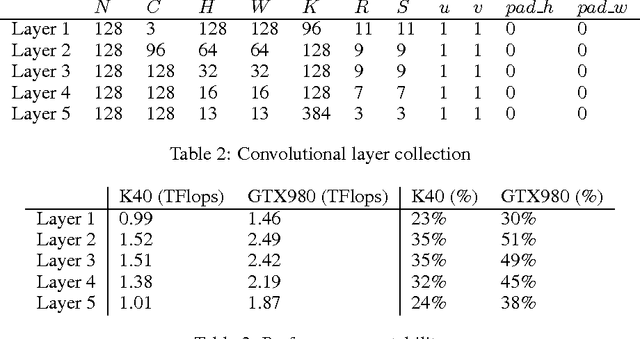
We present a library of efficient implementations of deep learning primitives. Deep learning workloads are computationally intensive, and optimizing their kernels is difficult and time-consuming. As parallel architectures evolve, kernels must be reoptimized, which makes maintaining codebases difficult over time. Similar issues have long been addressed in the HPC community by libraries such as the Basic Linear Algebra Subroutines (BLAS). However, there is no analogous library for deep learning. Without such a library, researchers implementing deep learning workloads on parallel processors must create and optimize their own implementations of the main computational kernels, and this work must be repeated as new parallel processors emerge. To address this problem, we have created a library similar in intent to BLAS, with optimized routines for deep learning workloads. Our implementation contains routines for GPUs, although similarly to the BLAS library, these routines could be implemented for other platforms. The library is easy to integrate into existing frameworks, and provides optimized performance and memory usage. For example, integrating cuDNN into Caffe, a popular framework for convolutional networks, improves performance by 36% on a standard model while also reducing memory consumption.