Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRF-based Named Entity Recognition @ICON 2013
Paper and Code
Sep 29, 2014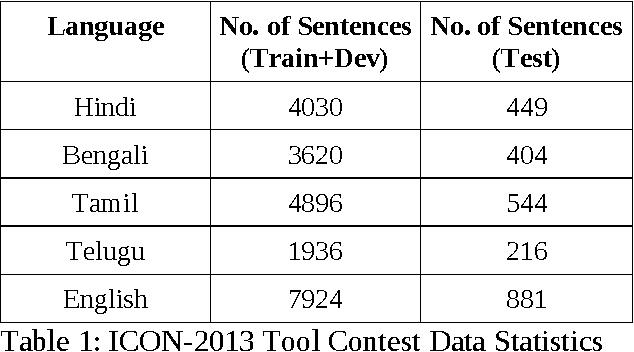
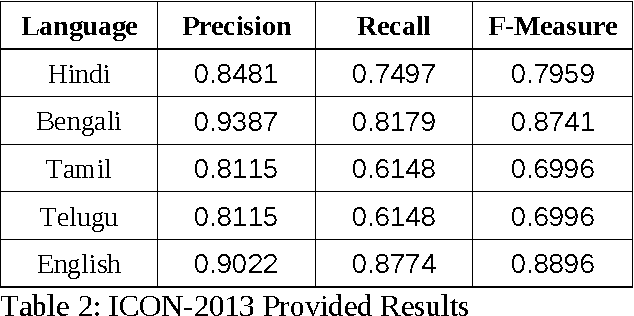
This paper describes performance of CRF based systems for Named Entity Recognition (NER) in Indian language as a part of ICON 2013 shared task. In this task we have considered a set of language independent features for all the languages. Only for English a language specific feature, i.e. capitalization, has been added. Next the use of gazetteer is explored for Bengali, Hindi and English. The gazetteers are built from Wikipedia and other sources. Test results show that the system achieves the highest F measure of 88% for English and the lowest F measure of 69% for both Tamil and Telugu. Note that for the least performing two languages no gazetteer was used. NER in Bengali and Hindi finds accuracy (F measure) of 87% and 79%, respectively.
View paper on