 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Cover Songs Using Information-Theoretic Measures of Similarity
Paper and Code
May 17, 2015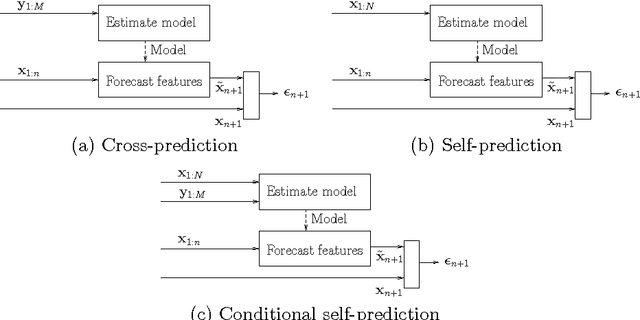
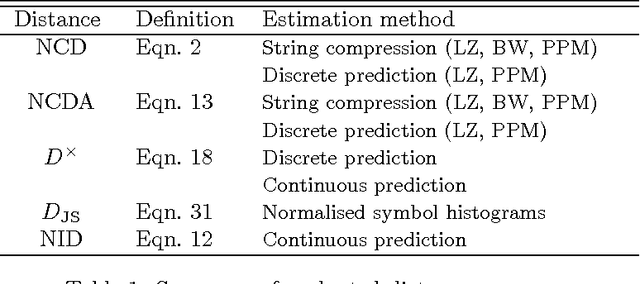
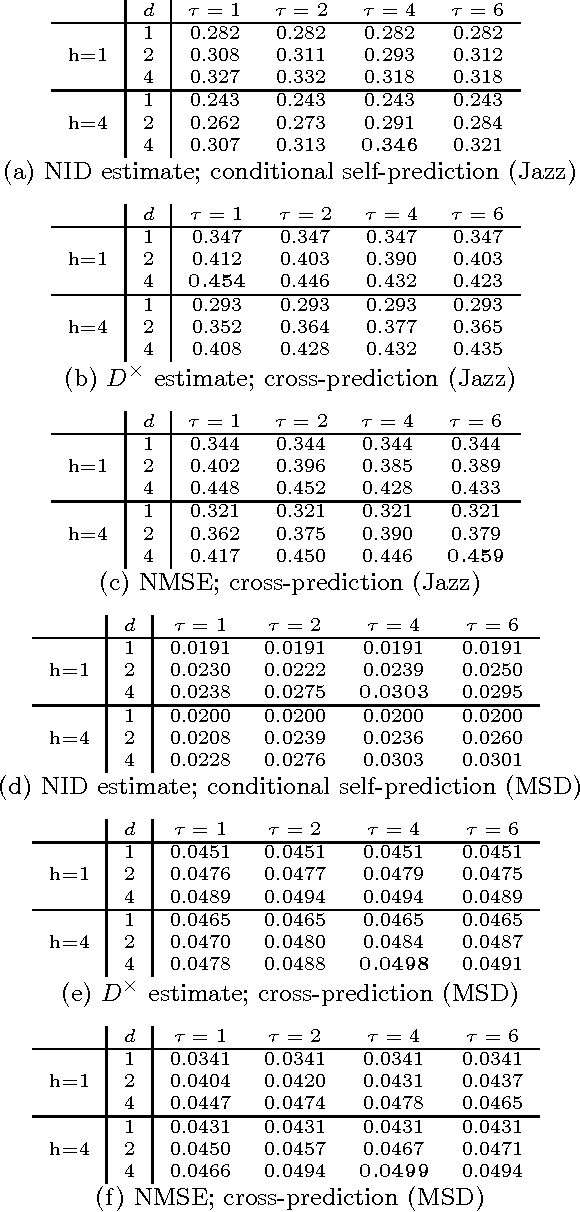
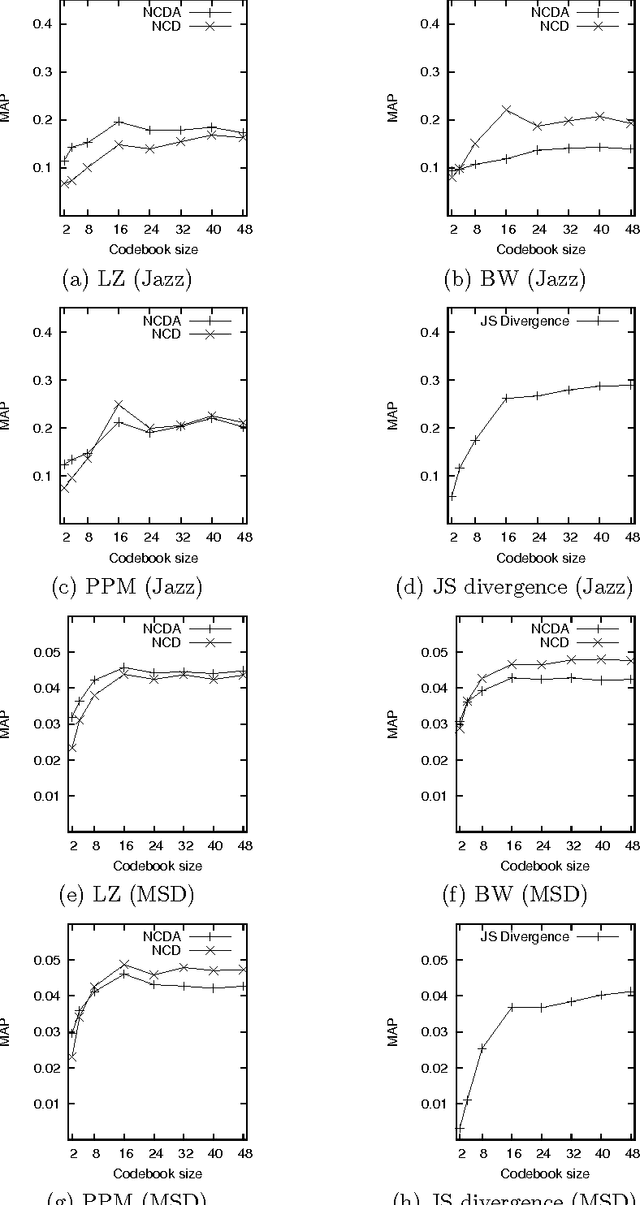
This paper investigates methods for quantifying similarity between audio signals, specifically for the task of of cover song detection. We consider an information-theoretic approach, where we compute pairwise measures of predictability between time series. We compare discrete-valued approaches operating on quantised audio features, to continuous-valued approaches. In the discrete case, we propose a method for computing the normalised compression distance, where we account for correlation between time series. In the continuous case, we propose to compute information-based measures of similarity as statistics of the prediction error between time series. We evaluate our methods on two cover song identification tasks using a data set comprised of 300 Jazz standards and using the Million Song Dataset. For both datasets, we observe that continuous-valued approaches outperform discrete-valued approaches. We consider approaches to estimating the normalised compression distance (NCD) based on string compression and prediction, where we observe that our proposed normalised compression distance with alignment (NCDA) improves average performance over NCD, for sequential compression algorithms. Finally, we demonstrate that continuous-valued distances may be combined to improve performance with respect to baseline approaches. Using a large-scale filter-and-refine approach, we demonstrate state-of-the-art performance for cover song identification using the Million Song Dataset.