 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature sampling and partitioning for visual vocabulary generation on large action classification datasets
Paper and Code
May 29, 2014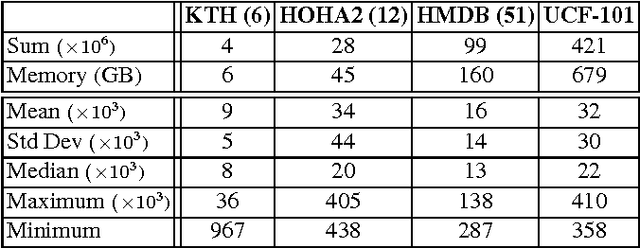
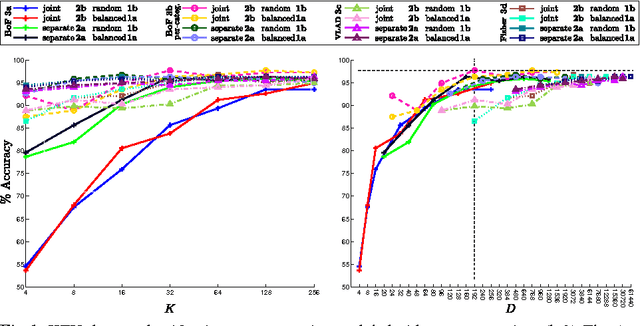
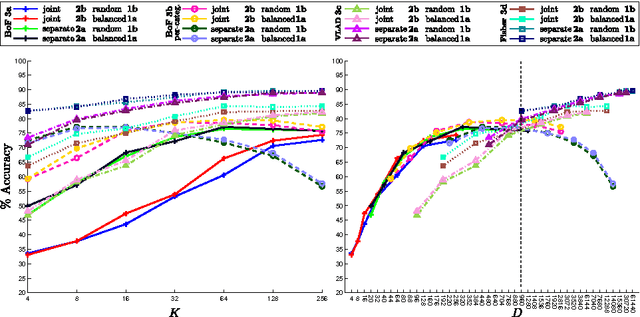
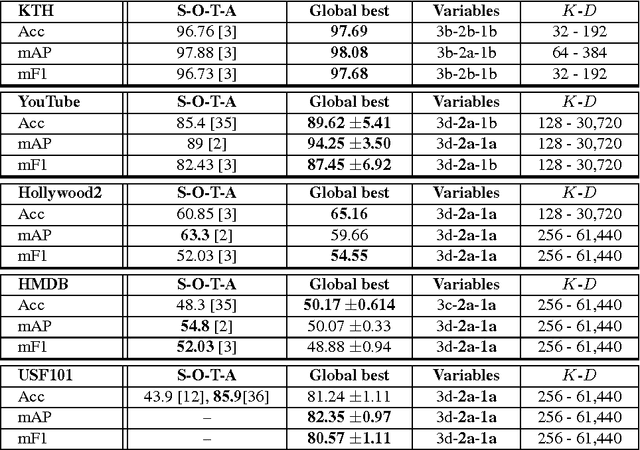
The recent trend in action recognition is towards larger datasets, an increasing number of action classes and larger visual vocabularies. State-of-the-art human action classification in challenging video data is currently based on a bag-of-visual-words pipeline in which space-time features are aggregated globally to form a histogram. The strategies chosen to sample features and construct a visual vocabulary are critical to performance, in fact often dominating performance. In this work we provide a critical evaluation of various approaches to building a vocabulary and show that good practises do have a significant impact. By subsampling and partitioning features strategically, we are able to achieve state-of-the-art results on 5 major action recognition datasets using relatively small visual vocabularies.