 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Joint Training Better for Deep Auto-Encoders?
Paper and Code
Jun 15, 2015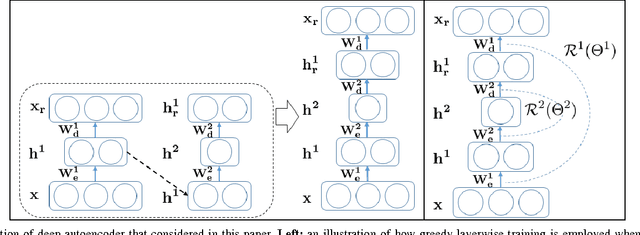
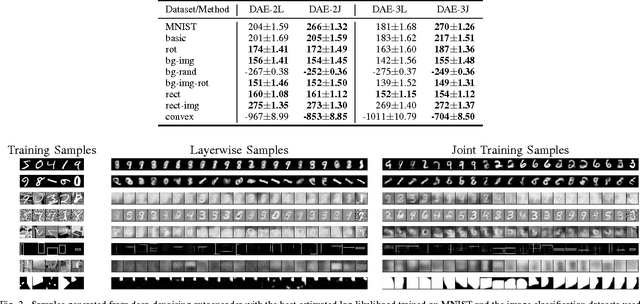
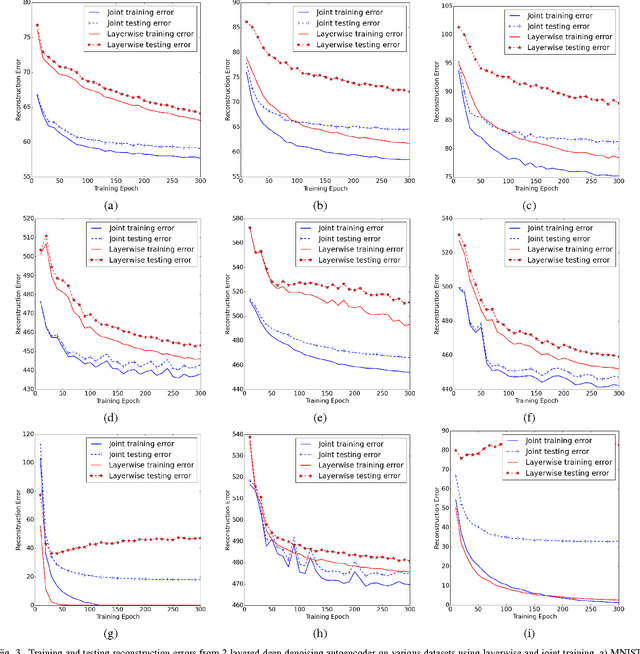

Traditionally, when generative models of data are developed via deep architectures, greedy layer-wise pre-training is employed. In a well-trained model, the lower layer of the architecture models the data distribution conditional upon the hidden variables, while the higher layers model the hidden distribution prior. But due to the greedy scheme of the layerwise training technique, the parameters of lower layers are fixed when training higher layers. This makes it extremely challenging for the model to learn the hidden distribution prior, which in turn leads to a suboptimal model for the data distribution. We therefore investigate joint training of deep autoencoders, where the architecture is viewed as one stack of two or more single-layer autoencoders. A single global reconstruction objective is jointly optimized, such that the objective for the single autoencoders at each layer acts as a local, layer-level regularizer. We empirically evaluate the performance of this joint training scheme and observe that it not only learns a better data model, but also learns better higher layer representations, which highlights its potential for unsupervised feature learning. In addition, we find that the usage of regularizations in the joint training scheme is crucial in achieving good performance. In the supervised setting, joint training also shows superior performance when training deeper models. The joint training framework can thus provide a platform for investigating more efficient usage of different types of regularizers, especially in light of the growing volumes of available unlabeled data.