 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing apples to apples in the evaluation of binary coding methods
Paper and Code
Sep 27, 2014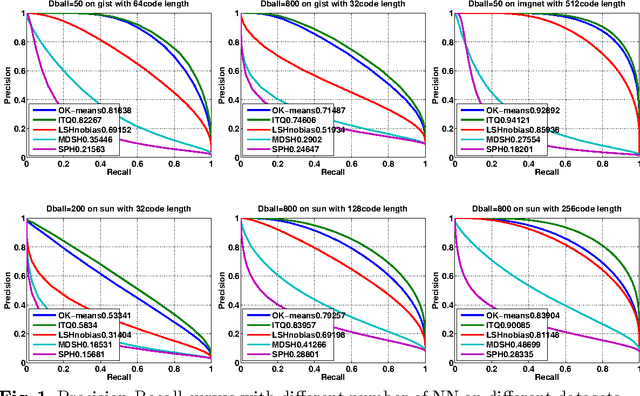
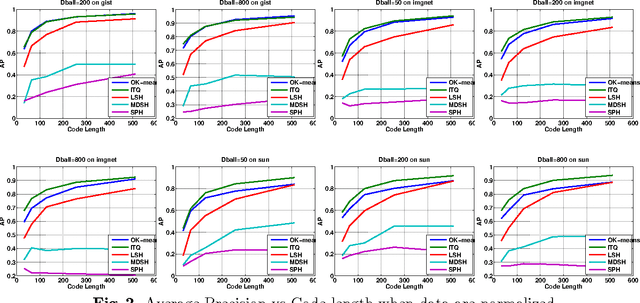
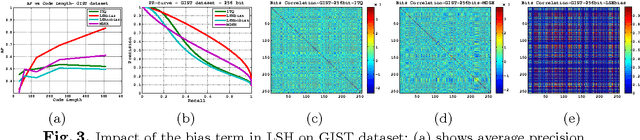
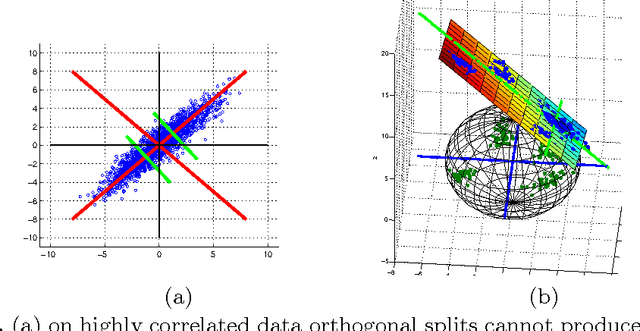
We discuss methodological issues related to the evaluation of unsupervised binary code construction methods for nearest neighbor search. These issues have been widely ignored in literature. These coding methods attempt to preserve either Euclidean distance or angular (cosine) distance in the binary embedding space. We explain why when comparing a method whose goal is preserving cosine similarity to one designed for preserving Euclidean distance, the original features should be normalized by mapping them to the unit hypersphere before learning the binary mapping functions. To compare a method whose goal is to preserves Euclidean distance to one that preserves cosine similarity, the original feature data must be mapped to a higher dimension by including a bias term in binary mapping functions. These conditions ensure the fair comparison between different binary code methods for the task of nearest neighbor search. Our experiments show under these conditions the very simple methods (e.g. LSH and ITQ) often outperform recent state-of-the-art methods (e.g. MDSH and OK-means).