 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Iteration for Decentralized Control of Markov Decision Processes
Paper and Code
Jan 15, 2014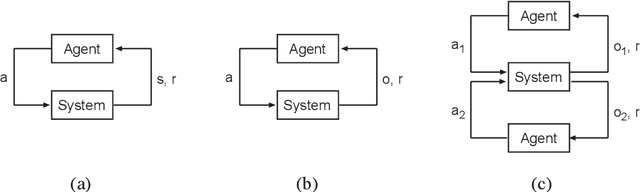
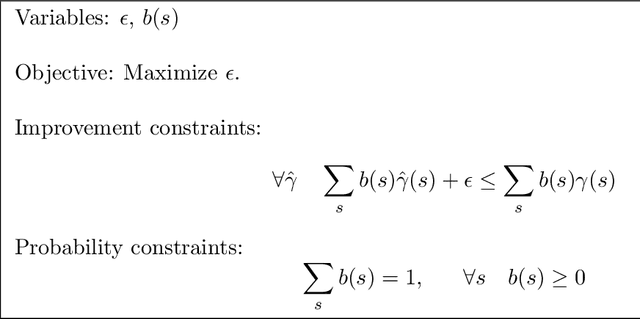
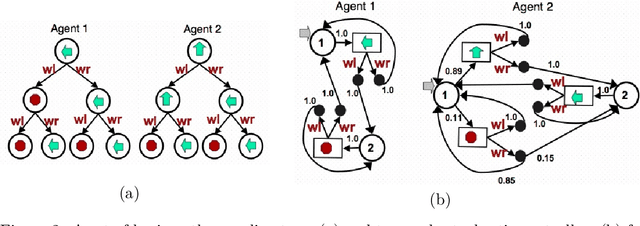
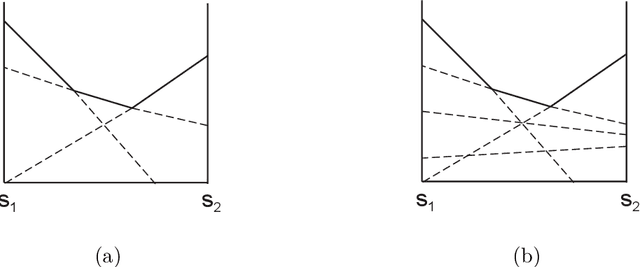
Coordination of distributed agents is required for problems arising in many areas, including multi-robot systems, networking and e-commerce. As a formal framework for such problems, we use the decentralized partially observable Markov decision process (DEC-POMDP). Though much work has been done on optimal dynamic programming algorithms for the single-agent version of the problem, optimal algorithms for the multiagent case have been elusive. The main contribution of this paper is an optimal policy iteration algorithm for solving DEC-POMDPs. The algorithm uses stochastic finite-state controllers to represent policies. The solution can include a correlation device, which allows agents to correlate their actions without communicating. This approach alternates between expanding the controller and performing value-preserving transformations, which modify the controller without sacrificing value. We present two efficient value-preserving transformations: one can reduce the size of the controller and the other can improve its value while keeping the size fixed. Empirical results demonstrate the usefulness of value-preserving transformations in increasing value while keeping controller size to a minimum. To broaden the applicability of the approach, we also present a heuristic version of the policy iteration algorithm, which sacrifices convergence to optimality. This algorithm further reduces the size of the controllers at each step by assuming that probability distributions over the other agents actions are known. While this assumption may not hold in general, it helps produce higher quality solutions in our test problems.