 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Connected Concepts from Biomedical Texts using Fog Index
Paper and Code
Jul 30, 2013
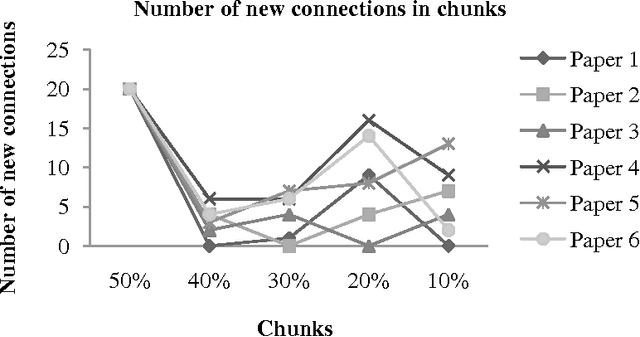
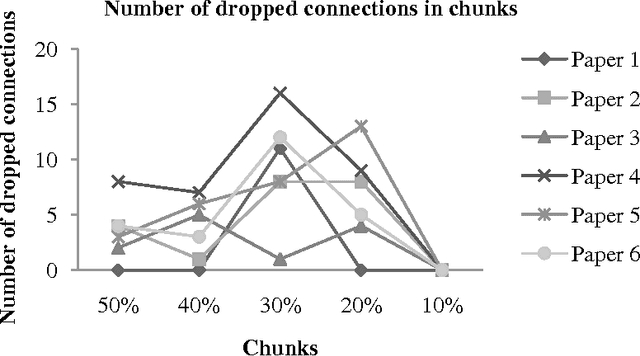
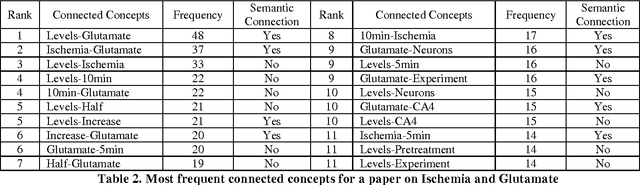
In this paper, we establish Fog Index (FI) as a text filter to locate the sentences in texts that contain connected biomedical concepts of interest. To do so, we have used 24 random papers each containing four pairs of connected concepts. For each pair, we categorize sentences based on whether they contain both, any or none of the concepts. We then use FI to measure difficulty of the sentences of each category and find that sentences containing both of the concepts have low readability. We rank sentences of a text according to their FI and select 30 percent of the most difficult sentences. We use an association matrix to track the most frequent pairs of concepts in them. This matrix reports that the first filter produces some pairs that hold almost no connections. To remove these unwanted pairs, we use the Equally Weighted Harmonic Mean of their Positive Predictive Value (PPV) and Sensitivity as a second filter. Experimental results demonstrate the effectiveness of our method.