 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance of Stanford and Minipar Parser on Biomedical Texts
Sep 25, 2014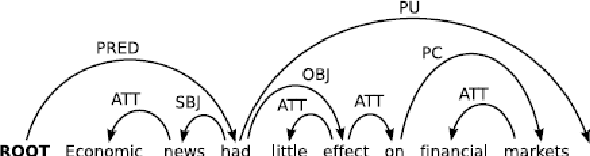

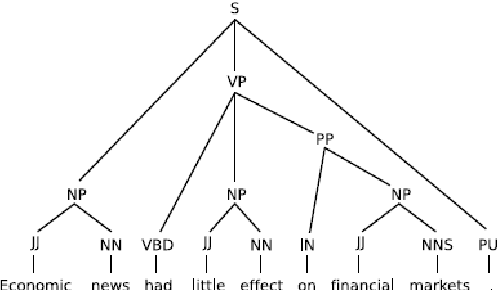
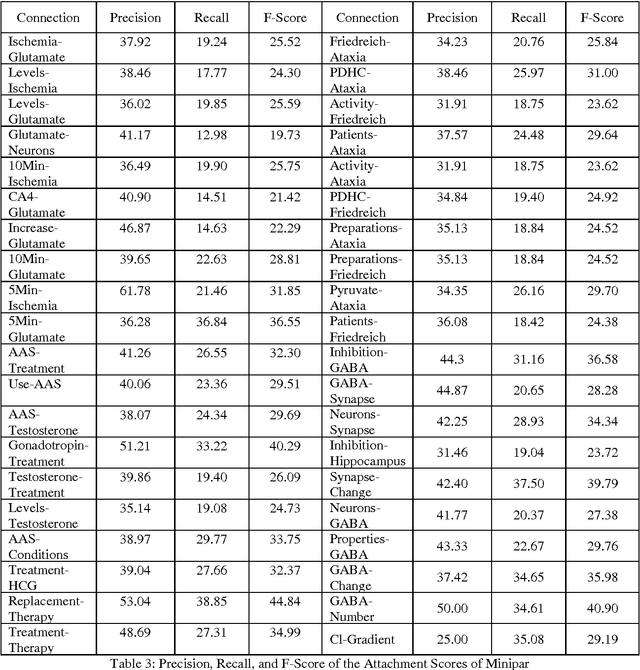
In this paper, the performance of two dependency parsers, namely Stanford and Minipar, on biomedical texts has been reported. The performance of te parsers to assignm dependencies between two biomedical concepts that are already proved to be connected is not satisfying. Both Stanford and Minipar, being statistical parsers, fail to assign dependency relation between two connected concepts if they are distant by at least one clause. Minipar's performance, in terms of precision, recall and the F-score of the attachment score (e.g., correctly identified head in a dependency), to parse biomedical text is also measured taking the Stanford's as a gold standard. The results suggest that Minipar is not suitable yet to parse biomedical texts. In addition, a qualitative investigation reveals that the difference between working principles of the parsers also play a vital role for Minipar's degraded performance.
Semi-supervised Classification for Natural Language Processing
Sep 25, 2014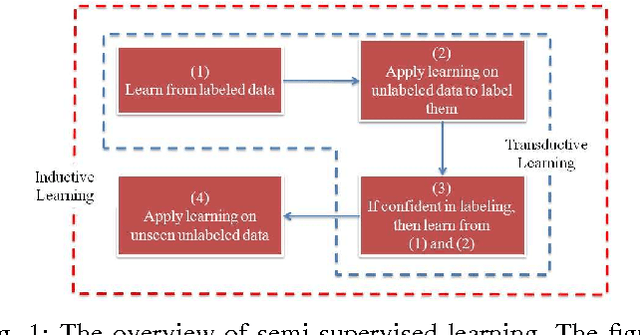
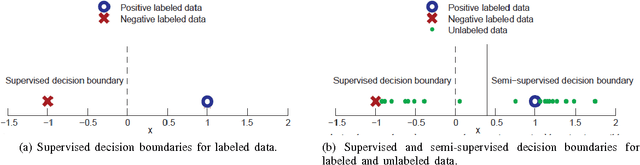

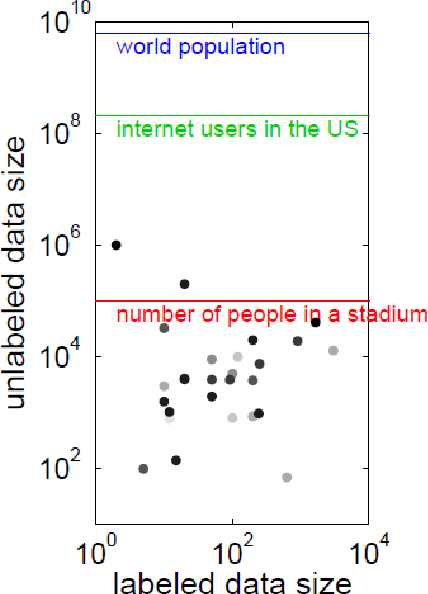
Semi-supervised classification is an interesting idea where classification models are learned from both labeled and unlabeled data. It has several advantages over supervised classification in natural language processing domain. For instance, supervised classification exploits only labeled data that are expensive, often difficult to get, inadequate in quantity, and require human experts for annotation. On the other hand, unlabeled data are inexpensive and abundant. Despite the fact that many factors limit the wide-spread use of semi-supervised classification, it has become popular since its level of performance is empirically as good as supervised classification. This study explores the possibilities and achievements as well as complexity and limitations of semi-supervised classification for several natural langue processing tasks like parsing, biomedical information processing, text classification, and summarization.
Extracting Information-rich Part of Texts using Text Denoising
Jul 30, 2013
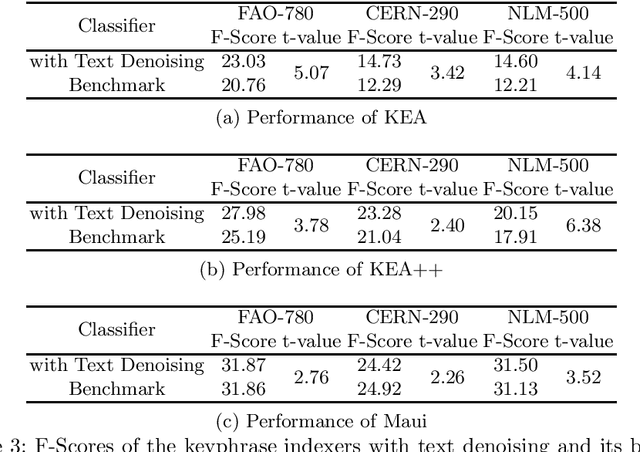

The aim of this paper is to report on a novel text reduction technique, called Text Denoising, that highlights information-rich content when processing a large volume of text data, especially from the biomedical domain. The core feature of the technique, the text readability index, embodies the hypothesis that complex text is more information-rich than the rest. When applied on tasks like biomedical relation bearing text extraction, keyphrase indexing and extracting sentences describing protein interactions, it is evident that the reduced set of text produced by text denoising is more information-rich than the rest.
Extracting Connected Concepts from Biomedical Texts using Fog Index
Jul 30, 2013
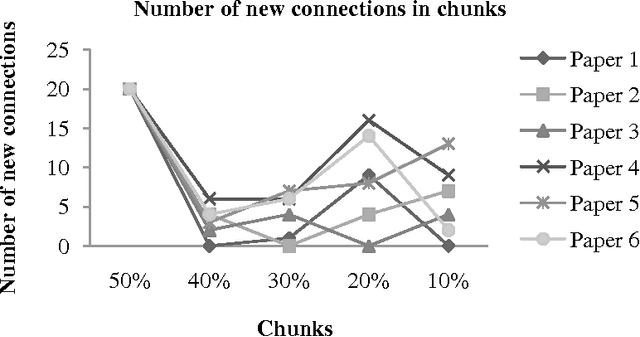
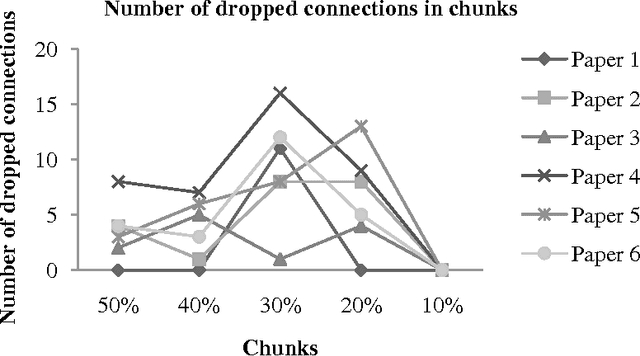
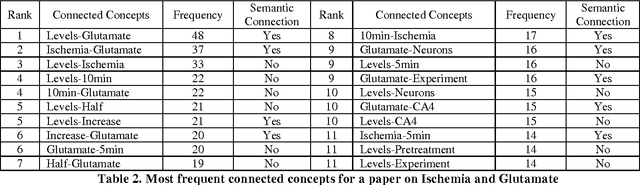
In this paper, we establish Fog Index (FI) as a text filter to locate the sentences in texts that contain connected biomedical concepts of interest. To do so, we have used 24 random papers each containing four pairs of connected concepts. For each pair, we categorize sentences based on whether they contain both, any or none of the concepts. We then use FI to measure difficulty of the sentences of each category and find that sentences containing both of the concepts have low readability. We rank sentences of a text according to their FI and select 30 percent of the most difficult sentences. We use an association matrix to track the most frequent pairs of concepts in them. This matrix reports that the first filter produces some pairs that hold almost no connections. To remove these unwanted pairs, we use the Equally Weighted Harmonic Mean of their Positive Predictive Value (PPV) and Sensitivity as a second filter. Experimental results demonstrate the effectiveness of our method.
Corpus-based Web Document Summarization using Statistical and Linguistic Approach
Apr 09, 2013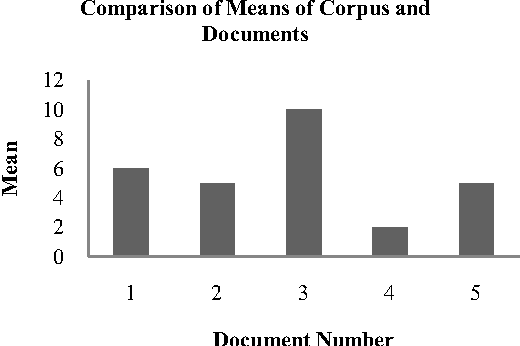
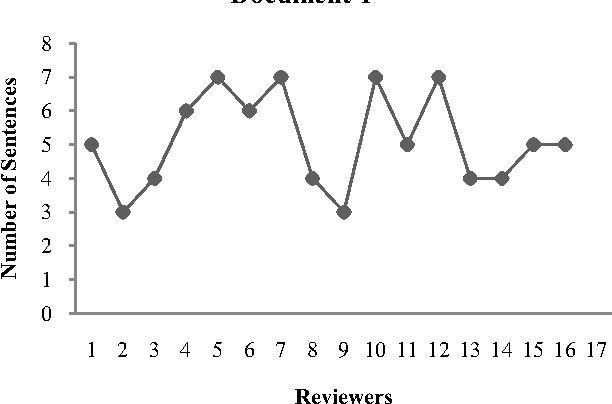
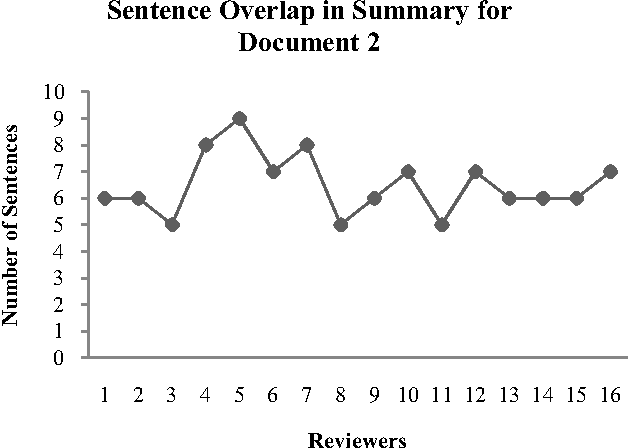
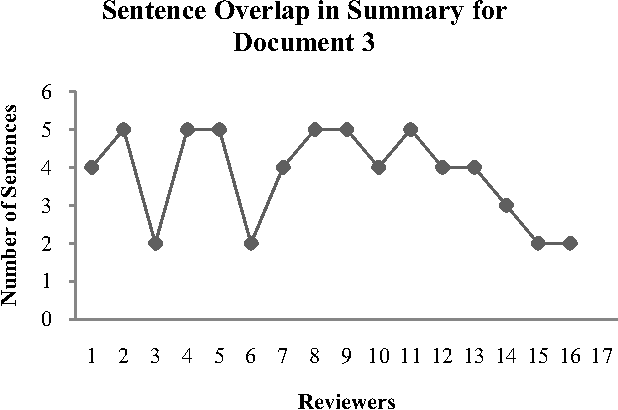
Single document summarization generates summary by extracting the representative sentences from the document. In this paper, we presented a novel technique for summarization of domain-specific text from a single web document that uses statistical and linguistic analysis on the text in a reference corpus and the web document. The proposed summarizer uses the combinational function of Sentence Weight (SW) and Subject Weight (SuW) to determine the rank of a sentence, where SW is the function of number of terms (t_n) and number of words (w_n) in a sentence, and term frequency (t_f) in the corpus and SuW is the function of t_n and w_n in a subject, and t_f in the corpus. 30 percent of the ranked sentences are considered to be the summary of the web document. We generated three web document summaries using our technique and compared each of them with the summaries developed manually from 16 different human subjects. Results showed that 68 percent of the summaries produced by our approach satisfy the manual summaries.
A Corpus-based Evaluation of a Domain-specific Text to Knowledge Mapping Prototype
Apr 28, 2012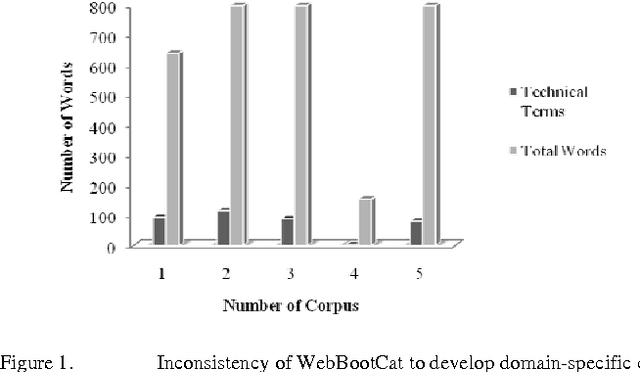
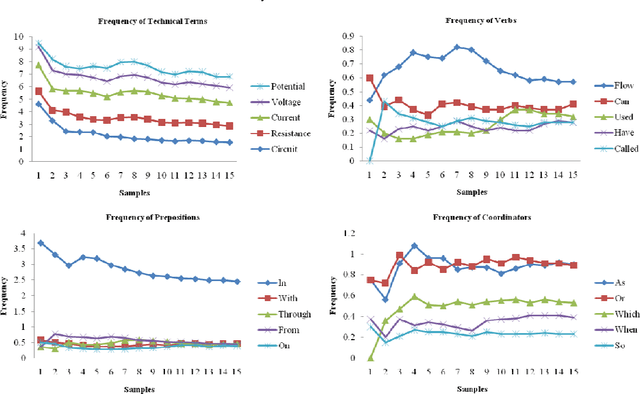
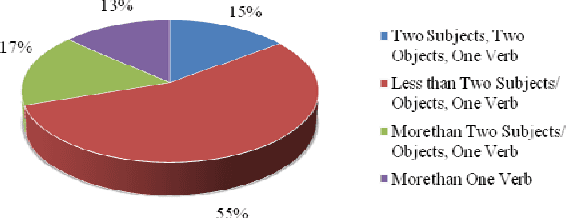
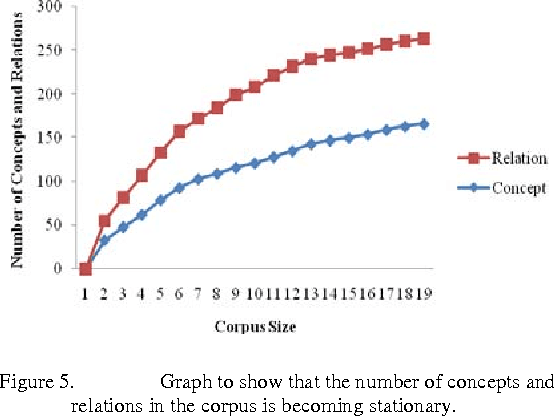
The aim of this paper is to evaluate a Text to Knowledge Mapping (TKM) Prototype. The prototype is domain-specific, the purpose of which is to map instructional text onto a knowledge domain. The context of the knowledge domain is DC electrical circuit. During development, the prototype has been tested with a limited data set from the domain. The prototype reached a stage where it needs to be evaluated with a representative linguistic data set called corpus. A corpus is a collection of text drawn from typical sources which can be used as a test data set to evaluate NLP systems. As there is no available corpus for the domain, we developed and annotated a representative corpus. The evaluation of the prototype considers two of its major components- lexical components and knowledge model. Evaluation on lexical components enriches the lexical resources of the prototype like vocabulary and grammar structures. This leads the prototype to parse a reasonable amount of sentences in the corpus. While dealing with the lexicon was straight forward, the identification and extraction of appropriate semantic relations was much more involved. It was necessary, therefore, to manually develop a conceptual structure for the domain to formulate a domain-specific framework of semantic relations. The framework of semantic relationsthat has resulted from this study consisted of 55 relations, out of which 42 have inverse relations. We also conducted rhetorical analysis on the corpus to prove its representativeness in conveying semantic. Finally, we conducted a topical and discourse analysis on the corpus to analyze the coverage of discourse by the prototype.
A Corpus-based Evaluation of Lexical Components of a Domainspecific Text to Knowledge Mapping Prototype
Apr 28, 2012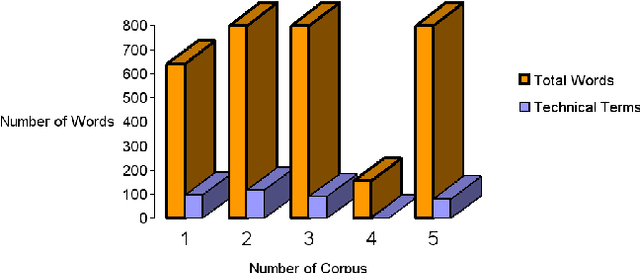
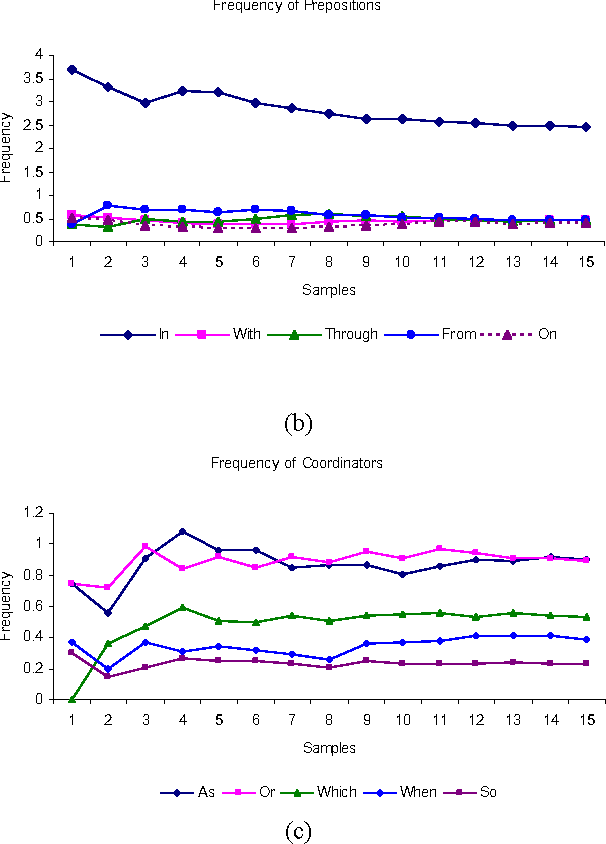
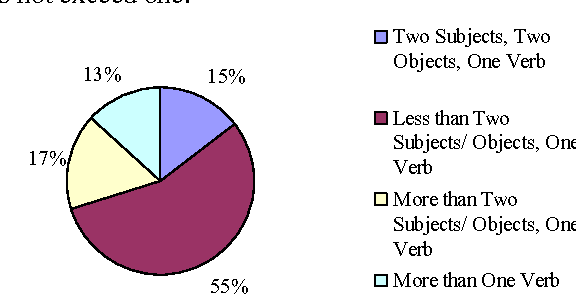
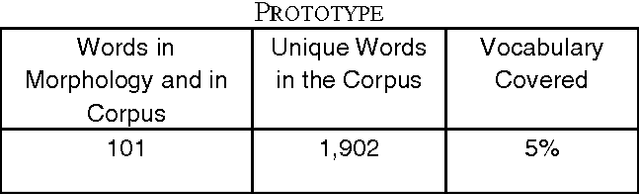
The aim of this paper is to evaluate the lexical components of a Text to Knowledge Mapping (TKM) prototype. The prototype is domain-specific, the purpose of which is to map instructional text onto a knowledge domain. The context of the knowledge domain of the prototype is physics, specifically DC electrical circuits. During development, the prototype has been tested with a limited data set from the domain. The prototype now reached a stage where it needs to be evaluated with a representative linguistic data set called corpus. A corpus is a collection of text drawn from typical sources which can be used as a test data set to evaluate NLP systems. As there is no available corpus for the domain, we developed a representative corpus and annotated it with linguistic information. The evaluation of the prototype considers one of its two main components- lexical knowledge base. With the corpus, the evaluation enriches the lexical knowledge resources like vocabulary and grammar structure. This leads the prototype to parse a reasonable amount of sentences in the corpus.