 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstructing Hierarchical Image-tags Bimodal Representations for Word Tags Alternative Choice
Paper and Code
Jul 04, 2013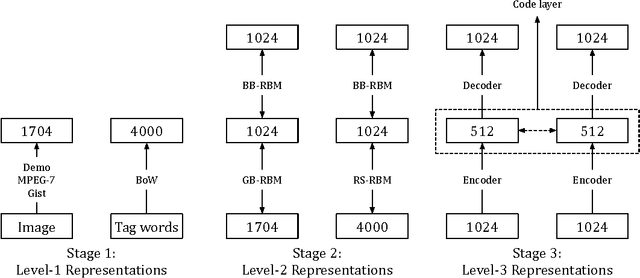

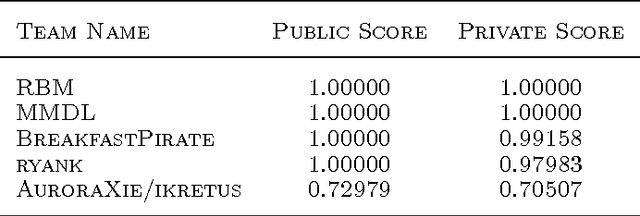
This paper describes our solution to the multi-modal learning challenge of ICML. This solution comprises constructing three-level representations in three consecutive stages and choosing correct tag words with a data-specific strategy. Firstly, we use typical methods to obtain level-1 representations. Each image is represented using MPEG-7 and gist descriptors with additional features released by the contest organizers. And the corresponding word tags are represented by bag-of-words model with a dictionary of 4000 words. Secondly, we learn the level-2 representations using two stacked RBMs for each modality. Thirdly, we propose a bimodal auto-encoder to learn the similarities/dissimilarities between the pairwise image-tags as level-3 representations. Finally, during the test phase, based on one observation of the dataset, we come up with a data-specific strategy to choose the correct tag words leading to a leap of an improved overall performance. Our final average accuracy on the private test set is 100%, which ranks the first place in this challenge.