 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRiemannian metrics for neural networks II: recurrent networks and learning symbolic data sequences
Paper and Code
Feb 03, 2015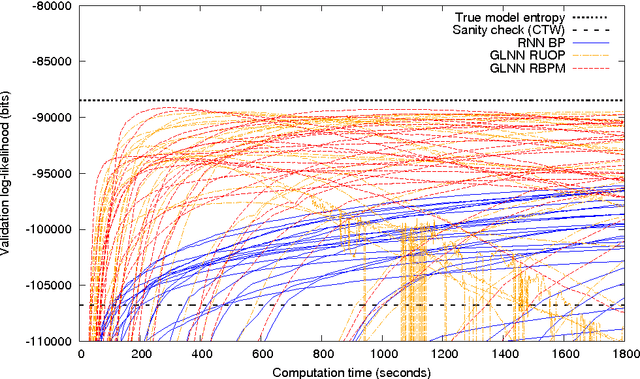
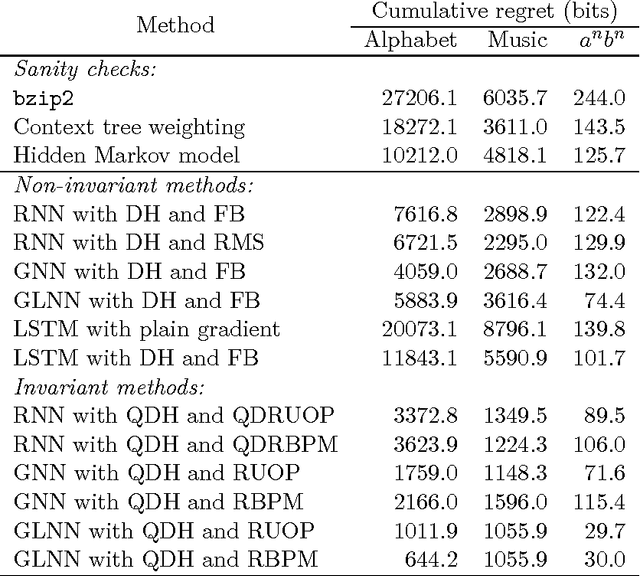
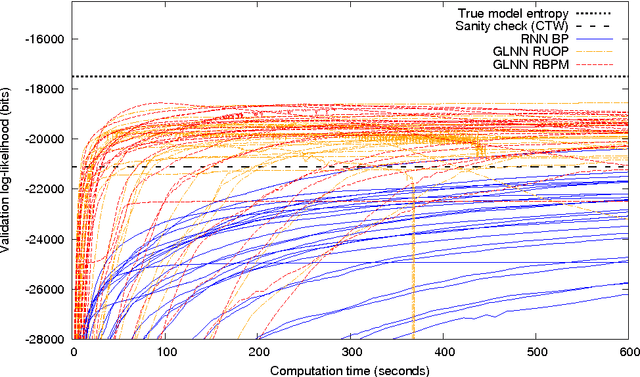
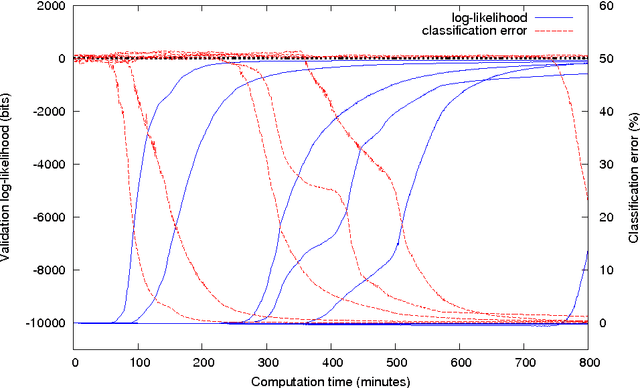
Recurrent neural networks are powerful models for sequential data, able to represent complex dependencies in the sequence that simpler models such as hidden Markov models cannot handle. Yet they are notoriously hard to train. Here we introduce a training procedure using a gradient ascent in a Riemannian metric: this produces an algorithm independent from design choices such as the encoding of parameters and unit activities. This metric gradient ascent is designed to have an algorithmic cost close to backpropagation through time for sparsely connected networks. We use this procedure on gated leaky neural networks (GLNNs), a variant of recurrent neural networks with an architecture inspired by finite automata and an evolution equation inspired by continuous-time networks. GLNNs trained with a Riemannian gradient are demonstrated to effectively capture a variety of structures in synthetic problems: basic block nesting as in context-free grammars (an important feature of natural languages, but difficult to learn), intersections of multiple independent Markov-type relations, or long-distance relationships such as the distant-XOR problem. This method does not require adjusting the network structure or initial parameters: the network used is a sparse random graph and the initialization is identical for all problems considered.