 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Intersection Trees
Paper and Code
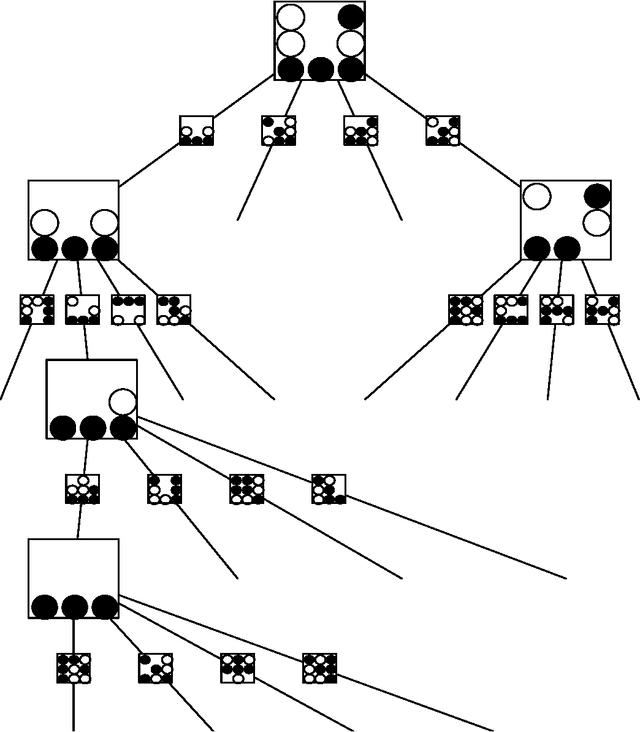
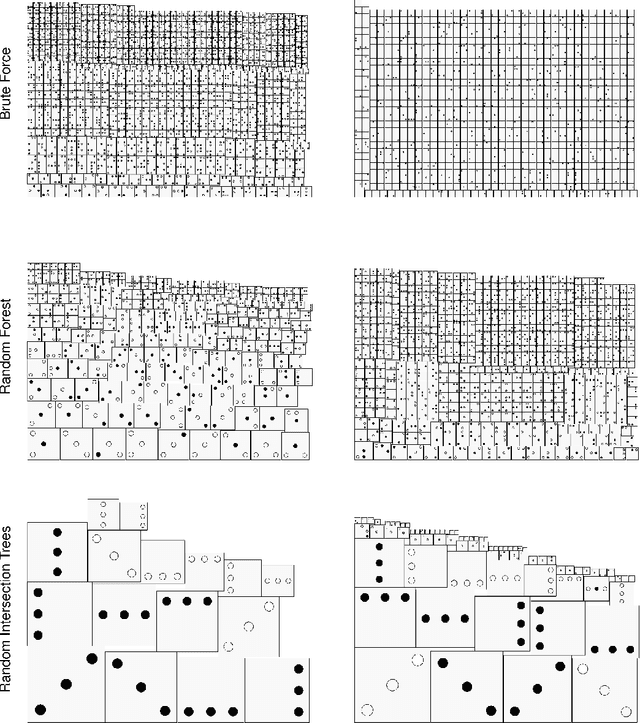
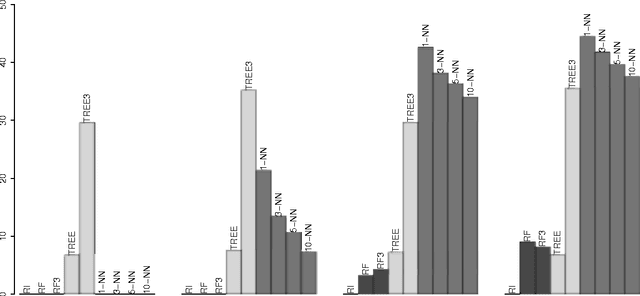
Finding interactions between variables in large and high-dimensional datasets is often a serious computational challenge. Most approaches build up interaction sets incrementally, adding variables in a greedy fashion. The drawback is that potentially informative high-order interactions may be overlooked. Here, we propose at an alternative approach for classification problems with binary predictor variables, called Random Intersection Trees. It works by starting with a maximal interaction that includes all variables, and then gradually removing variables if they fail to appear in randomly chosen observations of a class of interest. We show that informative interactions are retained with high probability, and the computational complexity of our procedure is of order $p^\kappa$ for a value of $\kappa$ that can reach values as low as 1 for very sparse data; in many more general settings, it will still beat the exponent $s$ obtained when using a brute force search constrained to order $s$ interactions. In addition, by using some new ideas based on min-wise hash schemes, we are able to further reduce the computational cost. Interactions found by our algorithm can be used for predictive modelling in various forms, but they are also often of interest in their own right as useful characterisations of what distinguishes a certain class from others.