 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtility Elicitation as a Classification Problem
Paper and Code
Jan 30, 2013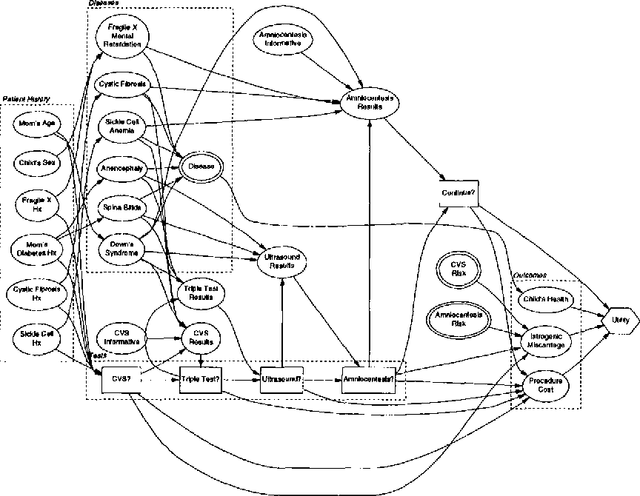
We investigate the application of classification techniques to utility elicitation. In a decision problem, two sets of parameters must generally be elicited: the probabilities and the utilities. While the prior and conditional probabilities in the model do not change from user to user, the utility models do. Thus it is necessary to elicit a utility model separately for each new user. Elicitation is long and tedious, particularly if the outcome space is large and not decomposable. There are two common approaches to utility function elicitation. The first is to base the determination of the users utility function solely ON elicitation OF qualitative preferences.The second makes assumptions about the form AND decomposability OF the utility function.Here we take a different approach: we attempt TO identify the new USERs utility function based on classification relative to a database of previously collected utility functions. We do this by identifying clusters of utility functions that minimize an appropriate distance measure. Having identified the clusters, we develop a classification scheme that requires many fewer and simpler assessments than full utility elicitation and is more robust than utility elicitation based solely on preferences. We have tested our algorithm on a small database of utility functions in a prenatal diagnosis domain and the results are quite promising.