Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Sentiment Strength in Words Prior Polarities
Paper and Code
Dec 18, 2012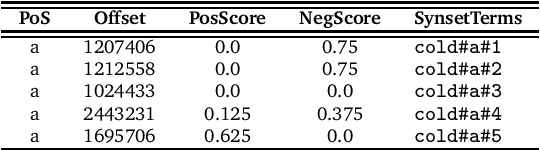



Many approaches to sentiment analysis rely on lexica where words are tagged with their prior polarity - i.e. if a word out of context evokes something positive or something negative. In particular, broad-coverage resources like SentiWordNet provide polarities for (almost) every word. Since words can have multiple senses, we address the problem of how to compute the prior polarity of a word starting from the polarity of each sense and returning its polarity strength as an index between -1 and 1. We compare 14 such formulae that appear in the literature, and assess which one best approximates the human judgement of prior polarities, with both regression and classification models.
* To appear at Coling 2012
View paper on