 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransition-Based Dependency Parsing With Pluggable Classifiers
Paper and Code
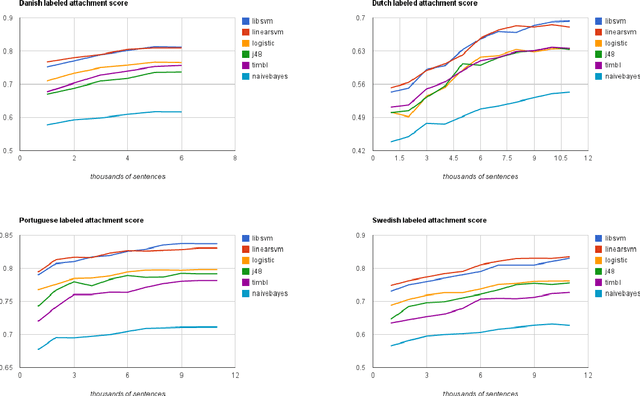
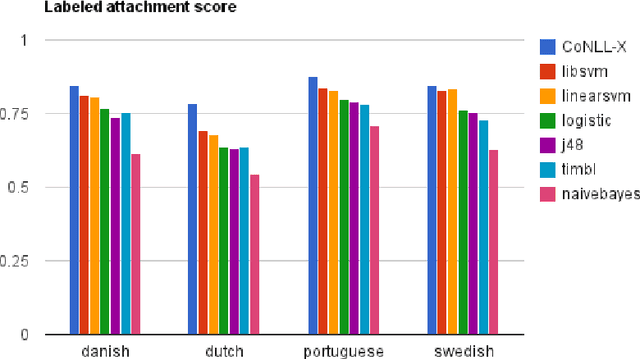

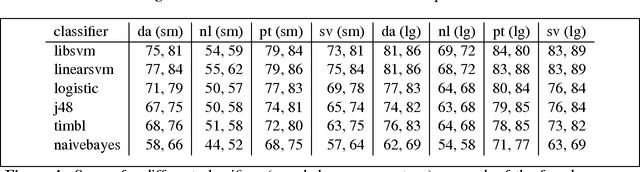
In principle, the design of transition-based dependency parsers makes it possible to experiment with any general-purpose classifier without other changes to the parsing algorithm. In practice, however, it often takes substantial software engineering to bridge between the different representations used by two software packages. Here we present extensions to MaltParser that allow the drop-in use of any classifier conforming to the interface of the Weka machine learning package, a wrapper for the TiMBL memory-based learner to this interface, and experiments on multilingual dependency parsing with a variety of classifiers. While earlier work had suggested that memory-based learners might be a good choice for low-resource parsing scenarios, we cannot support that hypothesis in this work. We observed that support-vector machines give better parsing performance than the memory-based learner, regardless of the size of the training set.