Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Is Better: Large Scale Partially-supervised Sentiment Classification - Appendix
Paper and Code
Sep 27, 2012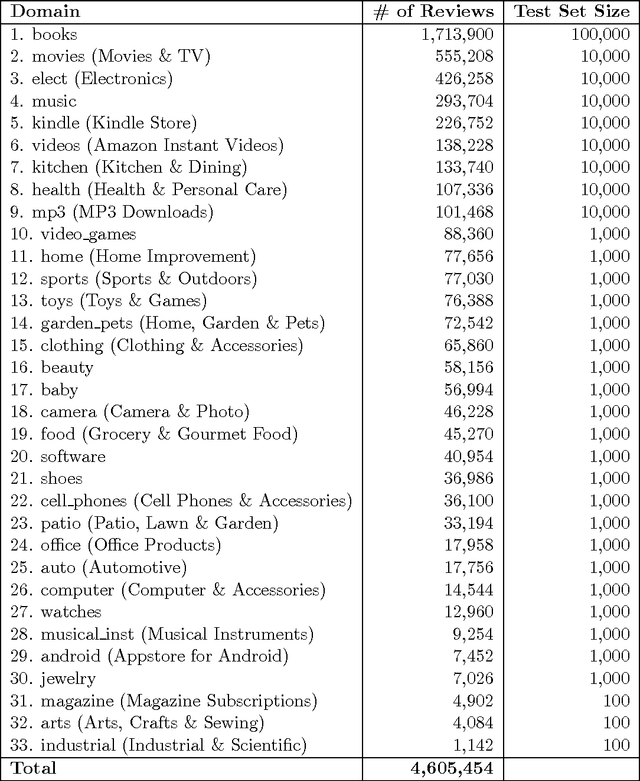
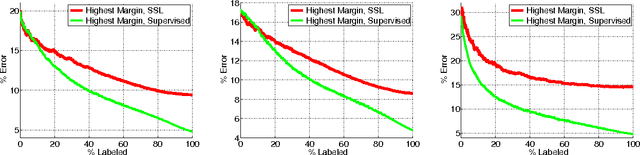
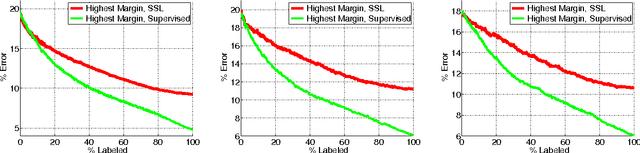
We describe a bootstrapping algorithm to learn from partially labeled data, and the results of an empirical study for using it to improve performance of sentiment classification using up to 15 million unlabeled Amazon product reviews. Our experiments cover semi-supervised learning, domain adaptation and weakly supervised learning. In some cases our methods were able to reduce test error by more than half using such large amount of data. NOTICE: This is only the supplementary material.
* This is the appendix to the paper "More Is Better: Large Scale
Partially-supervised Sentiment Classification" accepted to ACML 2012
View paper on