 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariable Selection for Latent Dirichlet Allocation
Paper and Code
May 04, 2012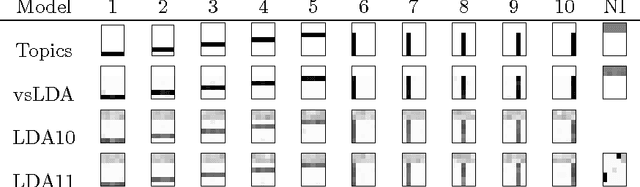
In latent Dirichlet allocation (LDA), topics are multinomial distributions over the entire vocabulary. However, the vocabulary usually contains many words that are not relevant in forming the topics. We adopt a variable selection method widely used in statistical modeling as a dimension reduction tool and combine it with LDA. In this variable selection model for LDA (vsLDA), topics are multinomial distributions over a subset of the vocabulary, and by excluding words that are not informative for finding the latent topic structure of the corpus, vsLDA finds topics that are more robust and discriminative. We compare three models, vsLDA, LDA with symmetric priors, and LDA with asymmetric priors, on heldout likelihood, MCMC chain consistency, and document classification. The performance of vsLDA is better than symmetric LDA for likelihood and classification, better than asymmetric LDA for consistency and classification, and about the same in the other comparisons.