 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Corpus-based Evaluation of Lexical Components of a Domainspecific Text to Knowledge Mapping Prototype
Paper and Code
Apr 28, 2012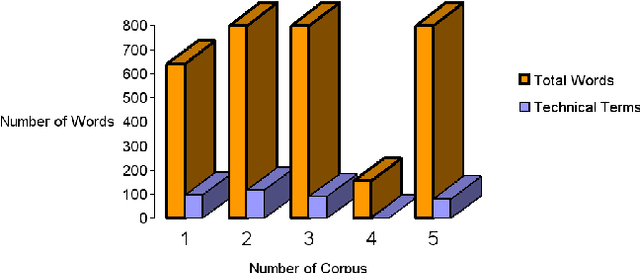
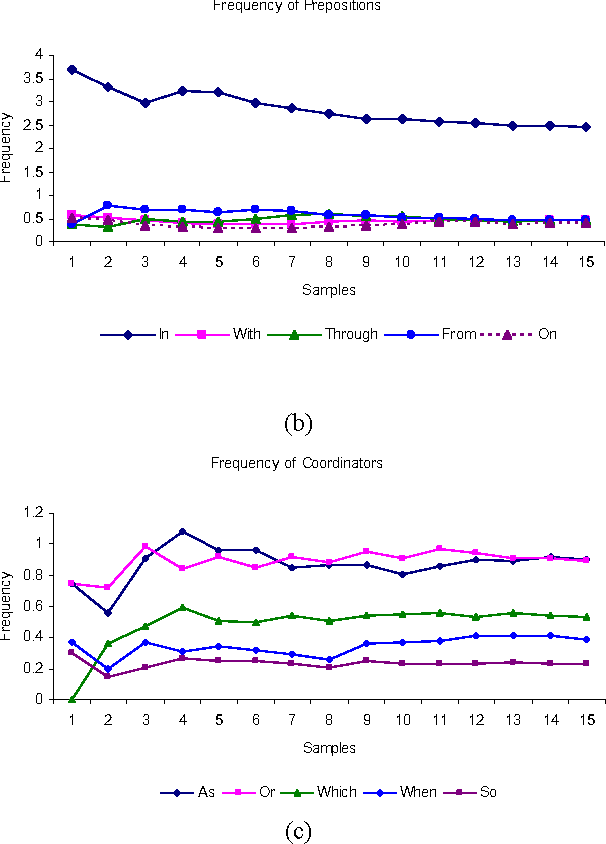
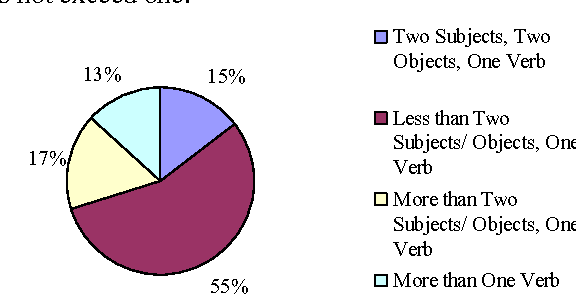
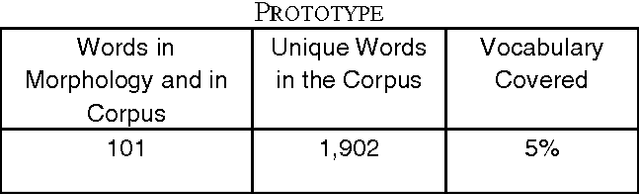
The aim of this paper is to evaluate the lexical components of a Text to Knowledge Mapping (TKM) prototype. The prototype is domain-specific, the purpose of which is to map instructional text onto a knowledge domain. The context of the knowledge domain of the prototype is physics, specifically DC electrical circuits. During development, the prototype has been tested with a limited data set from the domain. The prototype now reached a stage where it needs to be evaluated with a representative linguistic data set called corpus. A corpus is a collection of text drawn from typical sources which can be used as a test data set to evaluate NLP systems. As there is no available corpus for the domain, we developed a representative corpus and annotated it with linguistic information. The evaluation of the prototype considers one of its two main components- lexical knowledge base. With the corpus, the evaluation enriches the lexical knowledge resources like vocabulary and grammar structure. This leads the prototype to parse a reasonable amount of sentences in the corpus.