Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Accurate Arabic Root-Based Lemmatizer for Information Retrieval Purposes
Paper and Code
Mar 15, 2012
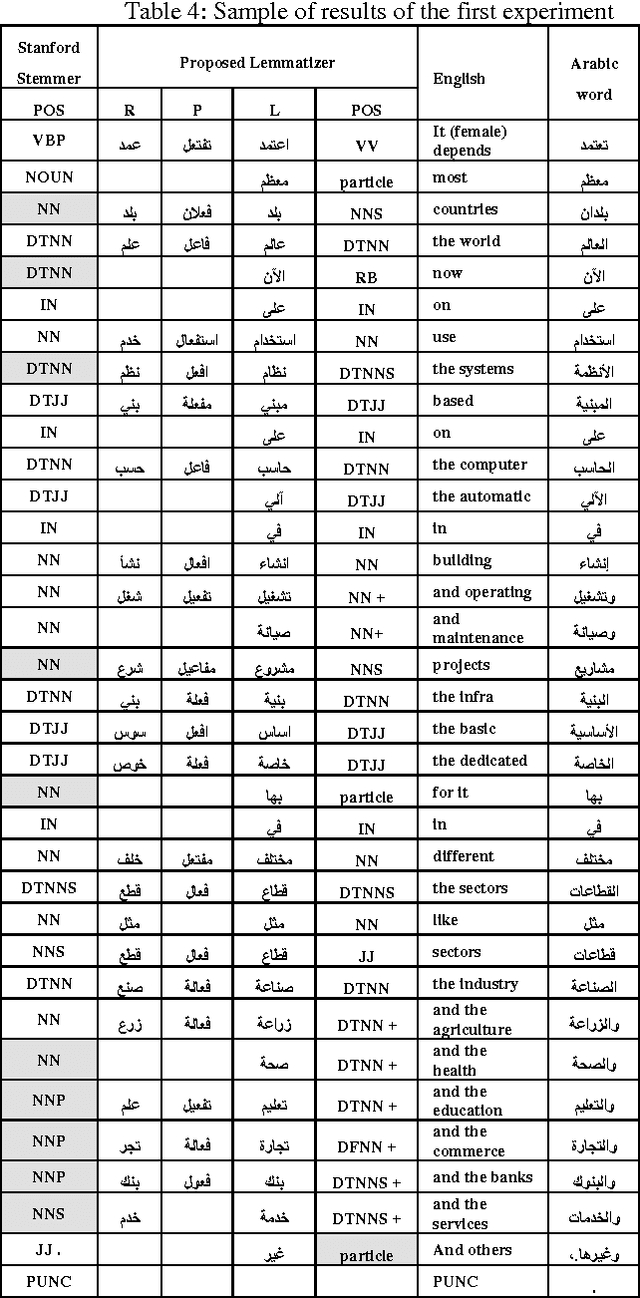
In spite of its robust syntax, semantic cohesion, and less ambiguity, lemma level analysis and generation does not yet focused in Arabic NLP literatures. In the current research, we propose the first non-statistical accurate Arabic lemmatizer algorithm that is suitable for information retrieval (IR) systems. The proposed lemmatizer makes use of different Arabic language knowledge resources to generate accurate lemma form and its relevant features that support IR purposes. As a POS tagger, the experimental results show that, the proposed algorithm achieves a maximum accuracy of 94.8%. For first seen documents, an accuracy of 89.15% is achieved, compared to 76.7% of up to date Stanford accurate Arabic model, for the same, dataset.
* IJCSI International Journal of Computer Science Issues, Vol. 9,
Issue 1, No 3, January 2012 ISSN (Online): 1694-0814 * 9 pages
View paper on