 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Lemma Based Evaluator for Semitic Language Text Summarization Systems
Mar 22, 2014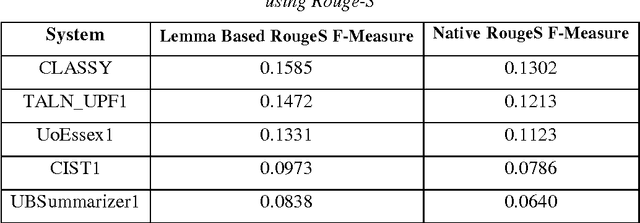
Matching texts in highly inflected languages such as Arabic by simple stemming strategy is unlikely to perform well. In this paper, we present a strategy for automatic text matching technique for for inflectional languages, using Arabic as the test case. The system is an extension of ROUGE test in which texts are matched on token's lemma level. The experimental results show an enhancement of detecting similarities between different sentences having same semantics but written in different lexical forms..
Multi-Topic Multi-Document Summarizer
Jan 03, 2014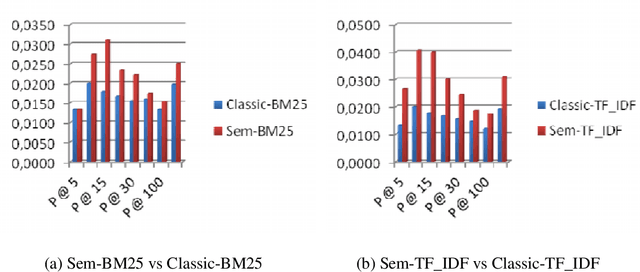
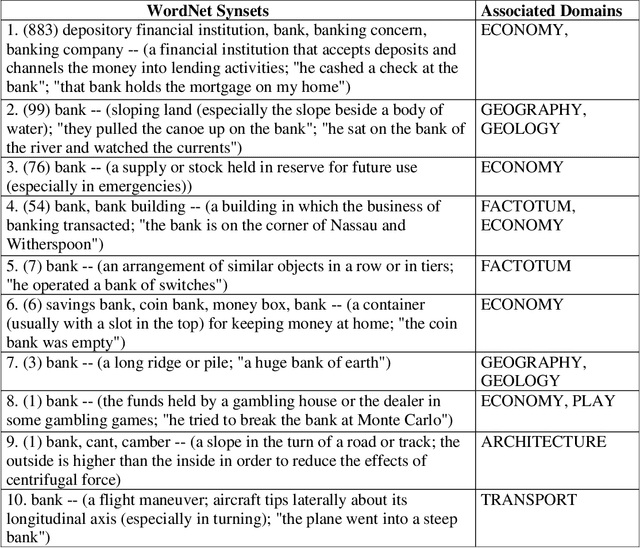
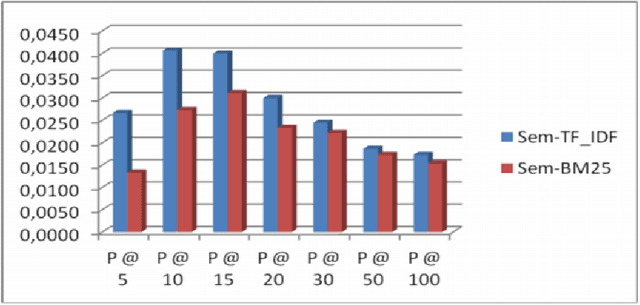
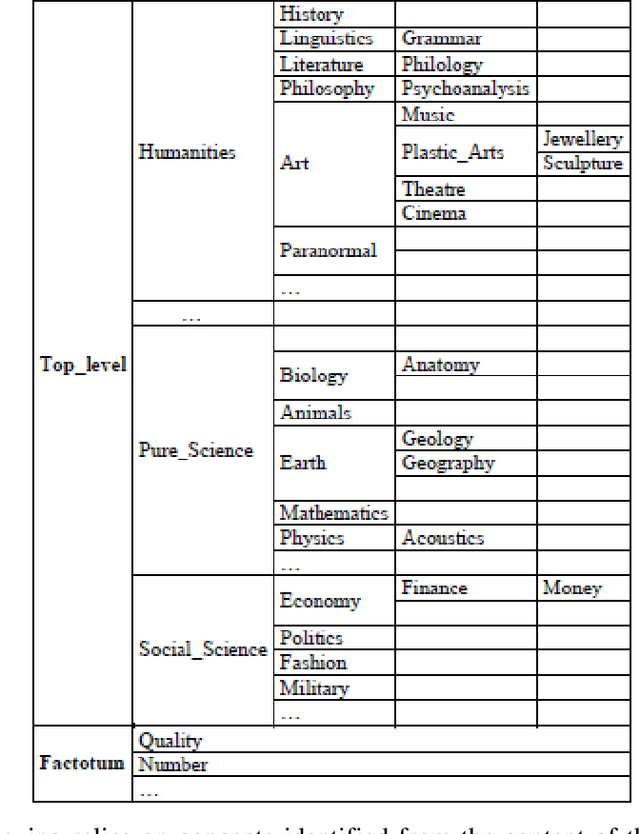
Current multi-document summarization systems can successfully extract summary sentences, however with many limitations including: low coverage, inaccurate extraction to important sentences, redundancy and poor coherence among the selected sentences. The present study introduces a new concept of centroid approach and reports new techniques for extracting summary sentences for multi-document. In both techniques keyphrases are used to weigh sentences and documents. The first summarization technique (Sen-Rich) prefers maximum richness sentences. While the second (Doc-Rich), prefers sentences from centroid document. To demonstrate the new summarization system application to extract summaries of Arabic documents we performed two experiments. First, we applied Rouge measure to compare the new techniques among systems presented at TAC2011. The results show that Sen-Rich outperformed all systems in ROUGE-S. Second, the system was applied to summarize multi-topic documents. Using human evaluators, the results show that Doc-Rich is the superior, where summary sentences characterized by extra coverage and more cohesion.
Keyphrase Based Arabic Summarizer (KPAS)
Jun 23, 2012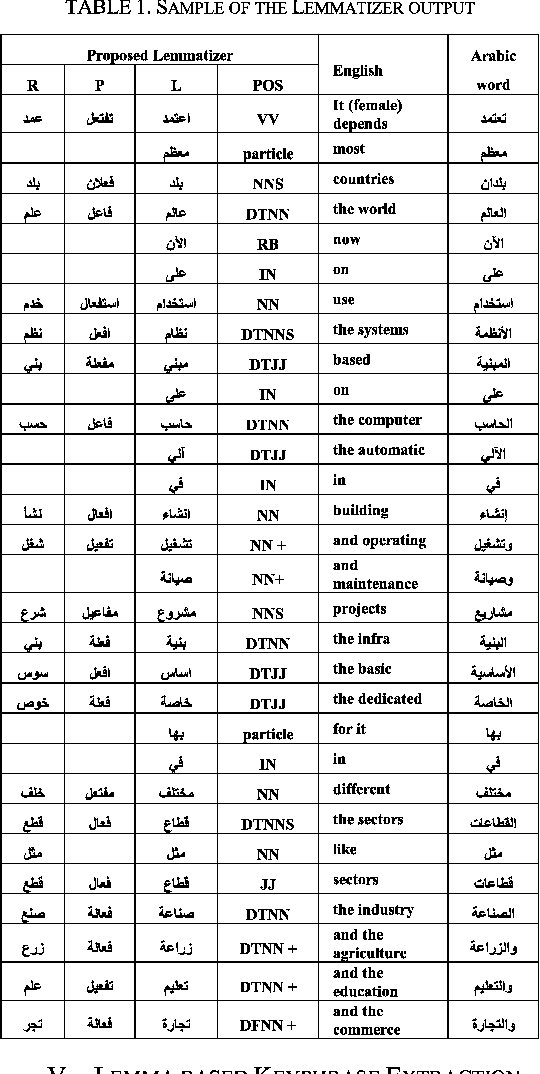

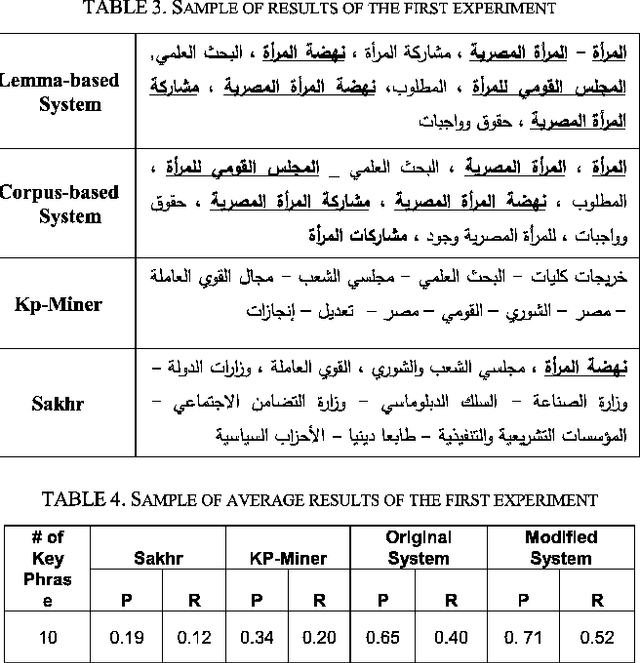
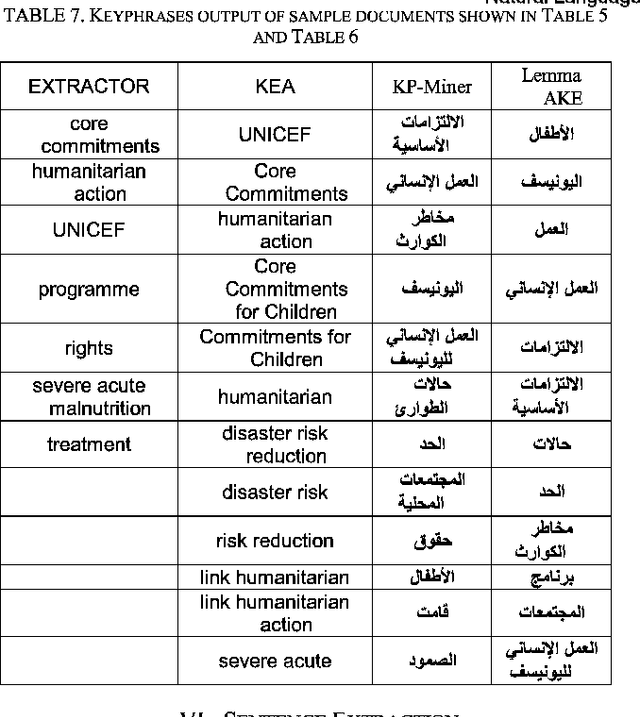
This paper describes a computationally inexpensive and efficient generic summarization algorithm for Arabic texts. The algorithm belongs to extractive summarization family, which reduces the problem into representative sentences identification and extraction sub-problems. Important keyphrases of the document to be summarized are identified employing combinations of statistical and linguistic features. The sentence extraction algorithm exploits keyphrases as the primary attributes to rank a sentence. The present experimental work, demonstrates different techniques for achieving various summarization goals including: informative richness, coverage of both main and auxiliary topics, and keeping redundancy to a minimum. A scoring scheme is then adopted that balances between these summarization goals. To evaluate the resulted Arabic summaries with well-established systems, aligned English/Arabic texts are used through the experiments.
An Accurate Arabic Root-Based Lemmatizer for Information Retrieval Purposes
Mar 15, 2012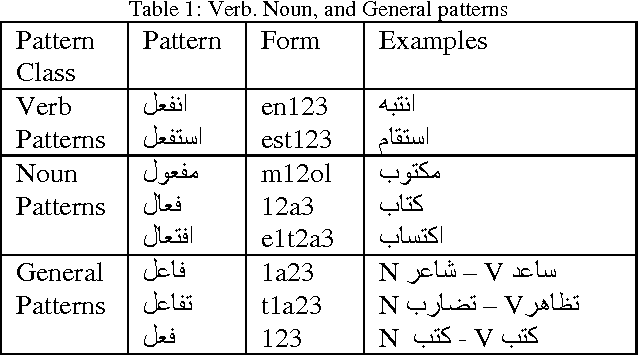
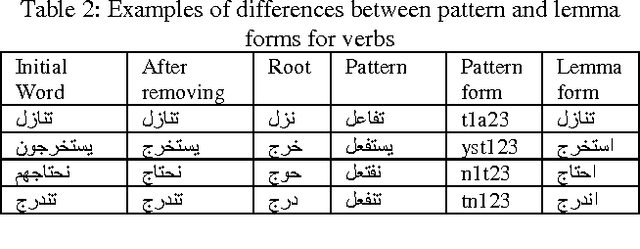
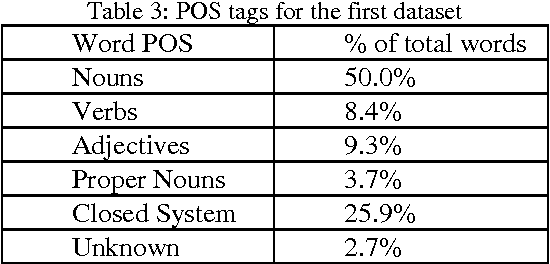
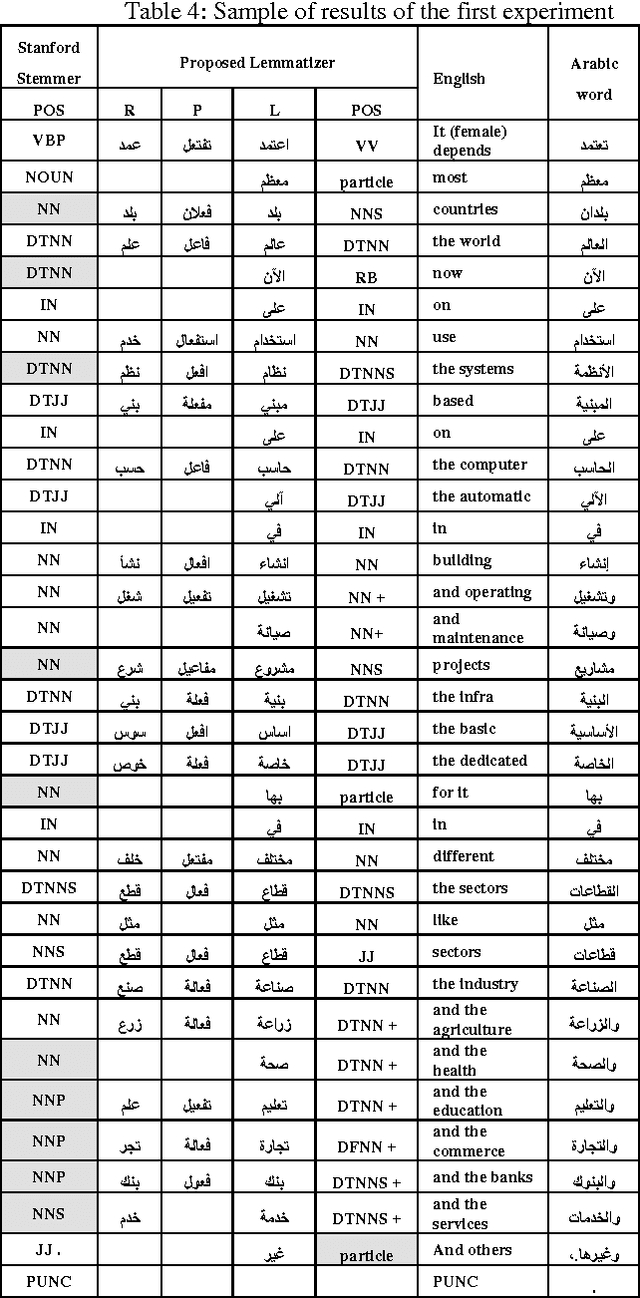
In spite of its robust syntax, semantic cohesion, and less ambiguity, lemma level analysis and generation does not yet focused in Arabic NLP literatures. In the current research, we propose the first non-statistical accurate Arabic lemmatizer algorithm that is suitable for information retrieval (IR) systems. The proposed lemmatizer makes use of different Arabic language knowledge resources to generate accurate lemma form and its relevant features that support IR purposes. As a POS tagger, the experimental results show that, the proposed algorithm achieves a maximum accuracy of 94.8%. For first seen documents, an accuracy of 89.15% is achieved, compared to 76.7% of up to date Stanford accurate Arabic model, for the same, dataset.
* 9 pages