 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Planning in Repeated Adversarial Games
Paper and Code
Mar 15, 2012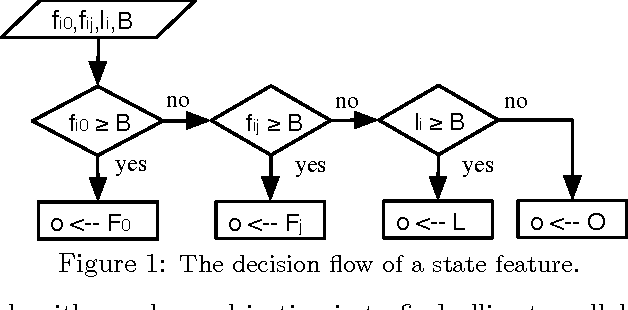
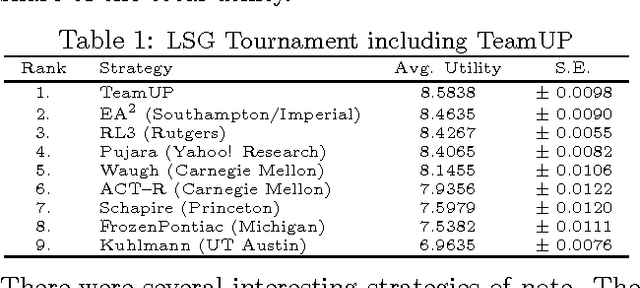
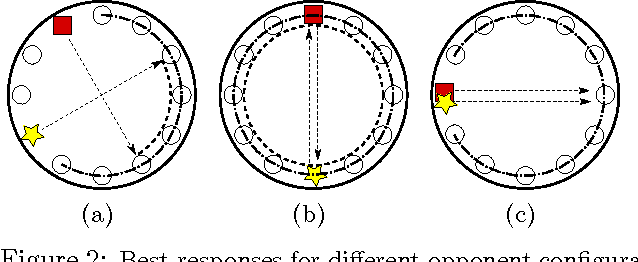

Game theory's prescriptive power typically relies on full rationality and/or self-play interactions. In contrast, this work sets aside these fundamental premises and focuses instead on heterogeneous autonomous interactions between two or more agents. Specifically, we introduce a new and concise representation for repeated adversarial (constant-sum) games that highlight the necessary features that enable an automated planing agent to reason about how to score above the game's Nash equilibrium, when facing heterogeneous adversaries. To this end, we present TeamUP, a model-based RL algorithm designed for learning and planning such an abstraction. In essence, it is somewhat similar to R-max with a cleverly engineered reward shaping that treats exploration as an adversarial optimization problem. In practice, it attempts to find an ally with which to tacitly collude (in more than two-player games) and then collaborates on a joint plan of actions that can consistently score a high utility in adversarial repeated games. We use the inaugural Lemonade Stand Game Tournament to demonstrate the effectiveness of our approach, and find that TeamUP is the best performing agent, demoting the Tournament's actual winning strategy into second place. In our experimental analysis, we show hat our strategy successfully and consistently builds collaborations with many different heterogeneous (and sometimes very sophisticated) adversaries.