 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Datalog for Machine Learning on Big Data
Paper and Code
Mar 02, 2012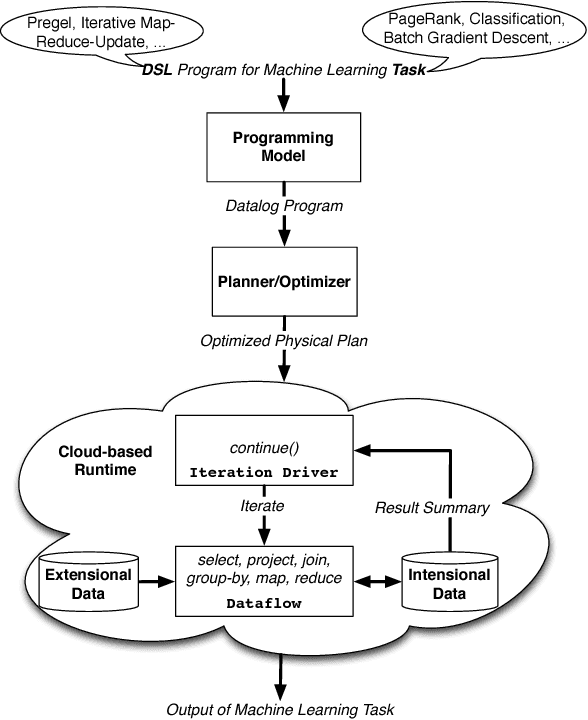
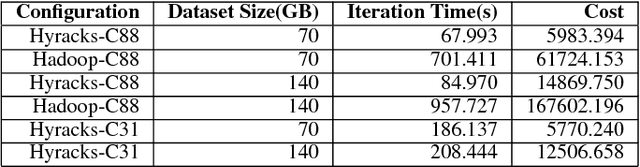
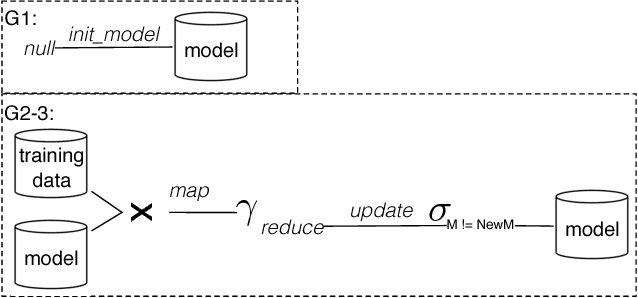
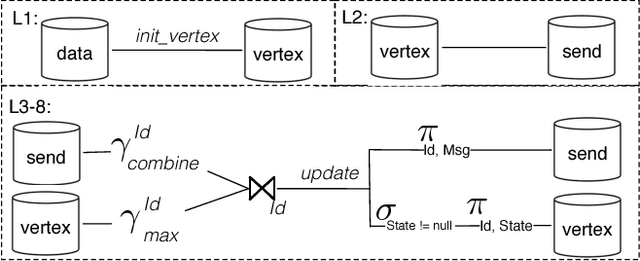
In this paper, we present the case for a declarative foundation for data-intensive machine learning systems. Instead of creating a new system for each specific flavor of machine learning task, or hardcoding new optimizations, we argue for the use of recursive queries to program a variety of machine learning systems. By taking this approach, database query optimization techniques can be utilized to identify effective execution plans, and the resulting runtime plans can be executed on a single unified data-parallel query processing engine. As a proof of concept, we consider two programming models--Pregel and Iterative Map-Reduce-Update---from the machine learning domain, and show how they can be captured in Datalog, tuned for a specific task, and then compiled into an optimized physical plan. Experiments performed on a large computing cluster with real data demonstrate that this declarative approach can provide very good performance while offering both increased generality and programming ease.