 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative MapReduce for Large Scale Machine Learning
Mar 13, 2013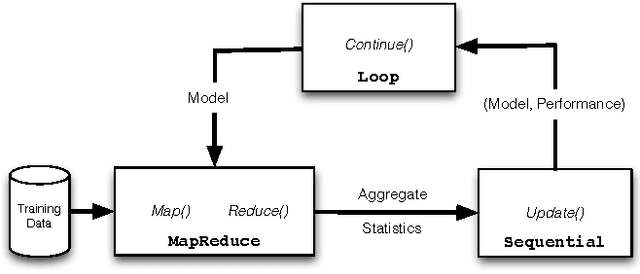

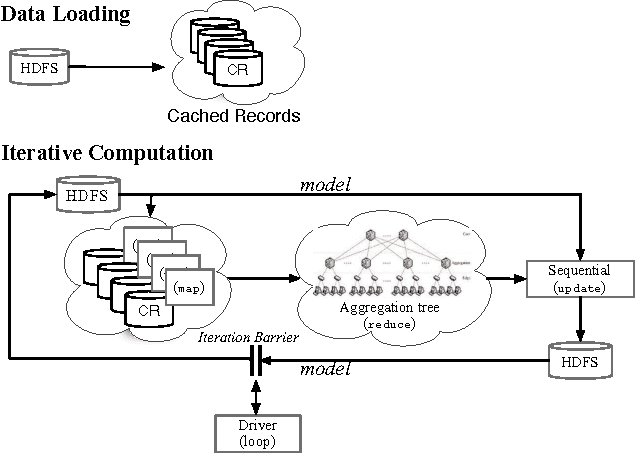

Large datasets ("Big Data") are becoming ubiquitous because the potential value in deriving insights from data, across a wide range of business and scientific applications, is increasingly recognized. In particular, machine learning - one of the foundational disciplines for data analysis, summarization and inference - on Big Data has become routine at most organizations that operate large clouds, usually based on systems such as Hadoop that support the MapReduce programming paradigm. It is now widely recognized that while MapReduce is highly scalable, it suffers from a critical weakness for machine learning: it does not support iteration. Consequently, one has to program around this limitation, leading to fragile, inefficient code. Further, reliance on the programmer is inherently flawed in a multi-tenanted cloud environment, since the programmer does not have visibility into the state of the system when his or her program executes. Prior work has sought to address this problem by either developing specialized systems aimed at stylized applications, or by augmenting MapReduce with ad hoc support for saving state across iterations (driven by an external loop). In this paper, we advocate support for looping as a first-class construct, and propose an extension of the MapReduce programming paradigm called {\em Iterative MapReduce}. We then develop an optimizer for a class of Iterative MapReduce programs that cover most machine learning techniques, provide theoretical justifications for the key optimization steps, and empirically demonstrate that system-optimized programs for significant machine learning tasks are competitive with state-of-the-art specialized solutions.
Scaling Datalog for Machine Learning on Big Data
Mar 02, 2012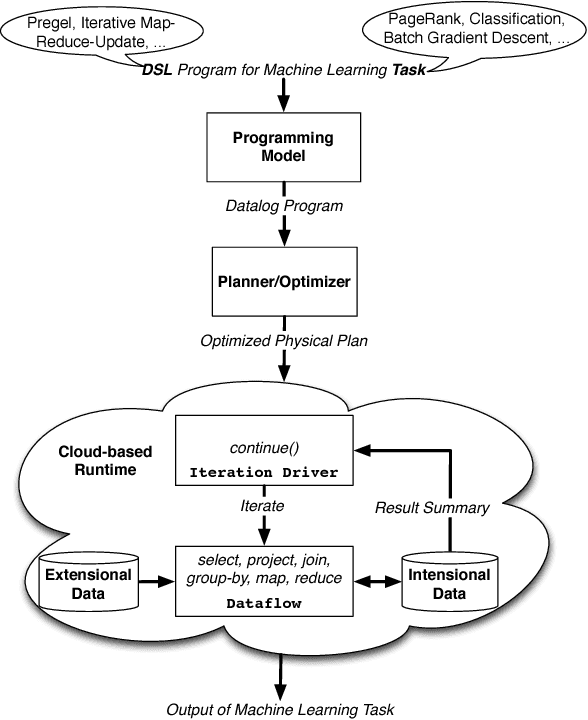
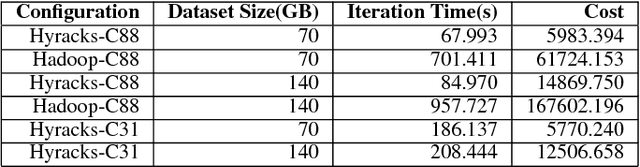
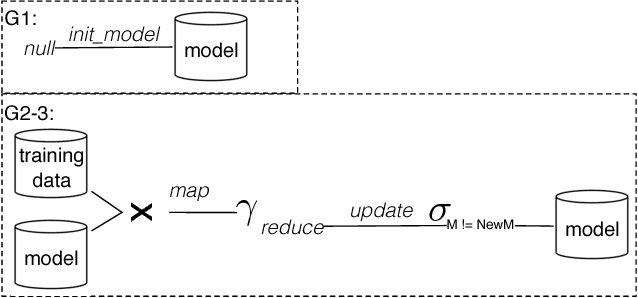
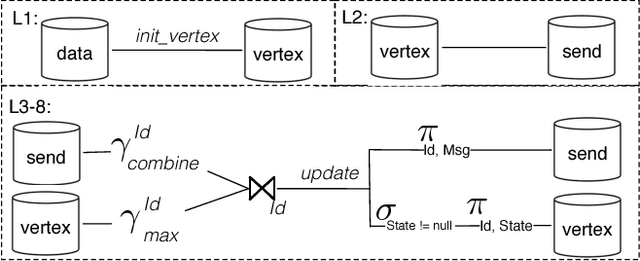
In this paper, we present the case for a declarative foundation for data-intensive machine learning systems. Instead of creating a new system for each specific flavor of machine learning task, or hardcoding new optimizations, we argue for the use of recursive queries to program a variety of machine learning systems. By taking this approach, database query optimization techniques can be utilized to identify effective execution plans, and the resulting runtime plans can be executed on a single unified data-parallel query processing engine. As a proof of concept, we consider two programming models--Pregel and Iterative Map-Reduce-Update---from the machine learning domain, and show how they can be captured in Datalog, tuned for a specific task, and then compiled into an optimized physical plan. Experiments performed on a large computing cluster with real data demonstrate that this declarative approach can provide very good performance while offering both increased generality and programming ease.