 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsembles of Kernel Predictors
Paper and Code
Feb 14, 2012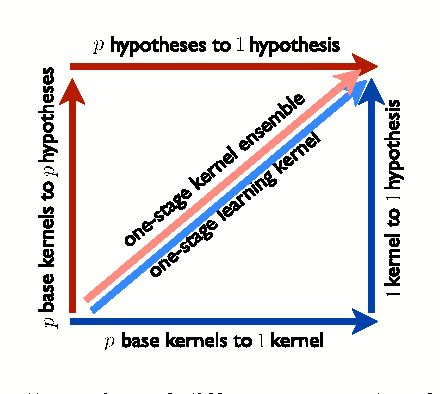
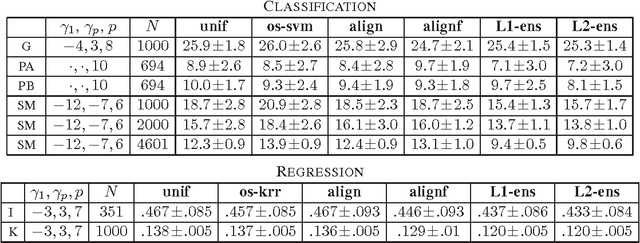
This paper examines the problem of learning with a finite and possibly large set of p base kernels. It presents a theoretical and empirical analysis of an approach addressing this problem based on ensembles of kernel predictors. This includes novel theoretical guarantees based on the Rademacher complexity of the corresponding hypothesis sets, the introduction and analysis of a learning algorithm based on these hypothesis sets, and a series of experiments using ensembles of kernel predictors with several data sets. Both convex combinations of kernel-based hypotheses and more general Lq-regularized nonnegative combinations are analyzed. These theoretical, algorithmic, and empirical results are compared with those achieved by using learning kernel techniques, which can be viewed as another approach for solving the same problem.