 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreating a Live, Public Short Message Service Corpus: The NUS SMS Corpus
Paper and Code
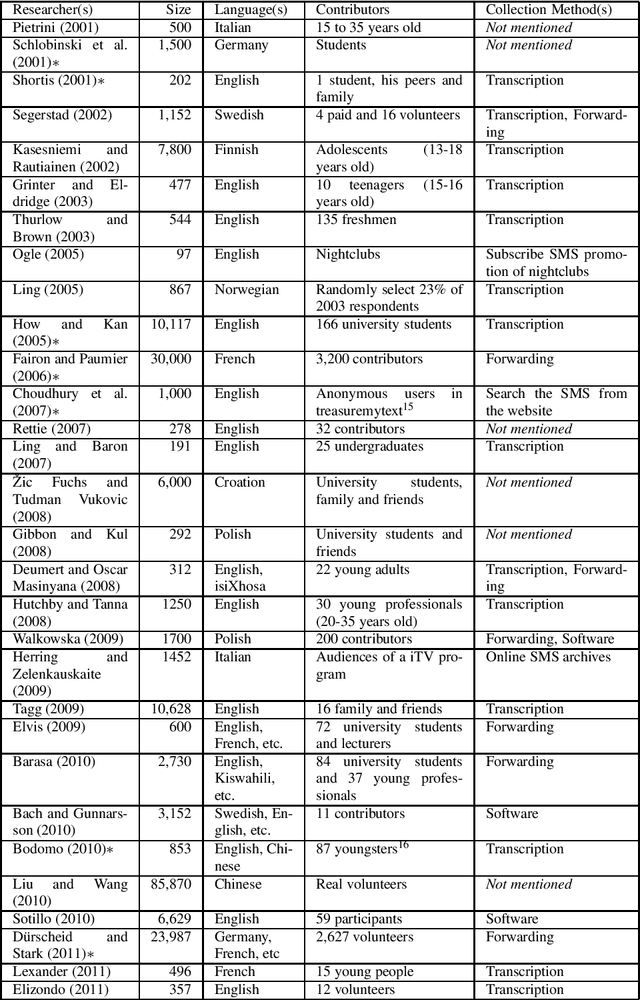

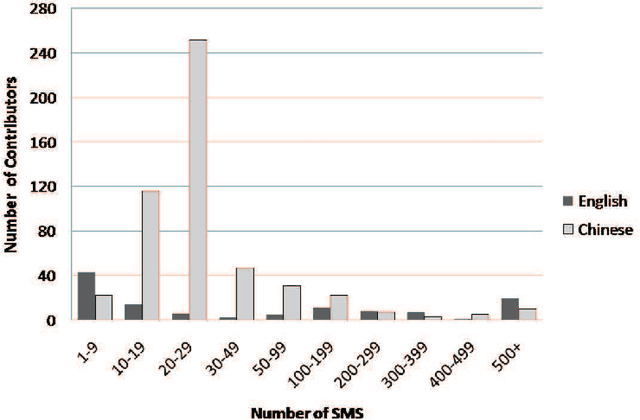
Short Message Service (SMS) messages are largely sent directly from one person to another from their mobile phones. They represent a means of personal communication that is an important communicative artifact in our current digital era. As most existing studies have used private access to SMS corpora, comparative studies using the same raw SMS data has not been possible up to now. We describe our efforts to collect a public SMS corpus to address this problem. We use a battery of methodologies to collect the corpus, paying particular attention to privacy issues to address contributors' concerns. Our live project collects new SMS message submissions, checks their quality and adds the valid messages, releasing the resultant corpus as XML and as SQL dumps, along with corpus statistics, every month. We opportunistically collect as much metadata about the messages and their sender as possible, so as to enable different types of analyses. To date, we have collected about 60,000 messages, focusing on English and Mandarin Chinese.