 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting k-means: New Algorithms via Bayesian Nonparametrics
Paper and Code
Jun 14, 2012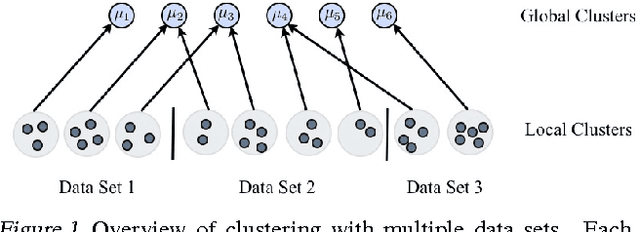
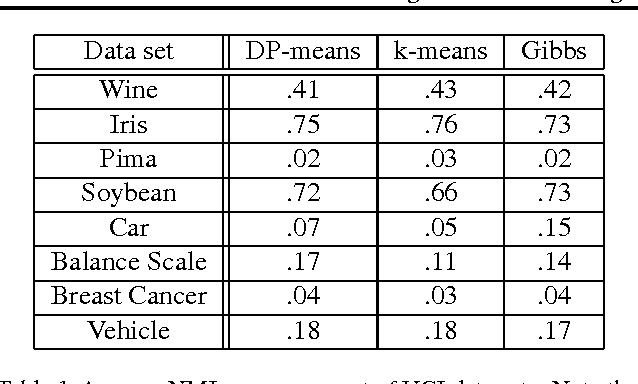
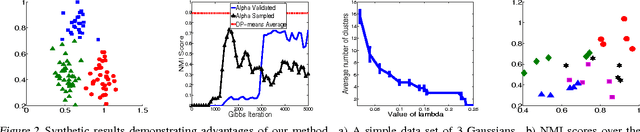
Bayesian models offer great flexibility for clustering applications---Bayesian nonparametrics can be used for modeling infinite mixtures, and hierarchical Bayesian models can be utilized for sharing clusters across multiple data sets. For the most part, such flexibility is lacking in classical clustering methods such as k-means. In this paper, we revisit the k-means clustering algorithm from a Bayesian nonparametric viewpoint. Inspired by the asymptotic connection between k-means and mixtures of Gaussians, we show that a Gibbs sampling algorithm for the Dirichlet process mixture approaches a hard clustering algorithm in the limit, and further that the resulting algorithm monotonically minimizes an elegant underlying k-means-like clustering objective that includes a penalty for the number of clusters. We generalize this analysis to the case of clustering multiple data sets through a similar asymptotic argument with the hierarchical Dirichlet process. We also discuss further extensions that highlight the benefits of our analysis: i) a spectral relaxation involving thresholded eigenvectors, and ii) a normalized cut graph clustering algorithm that does not fix the number of clusters in the graph.