 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Probabilities in Recommendation Systems
Paper and Code
Dec 02, 2010
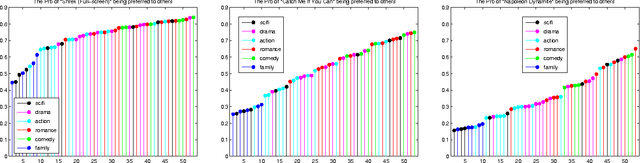
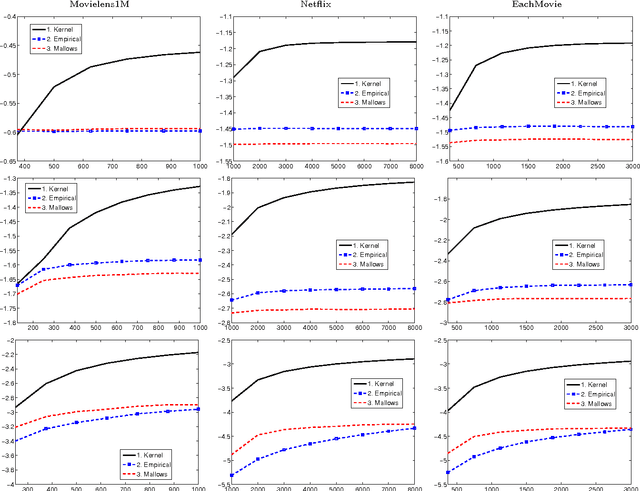
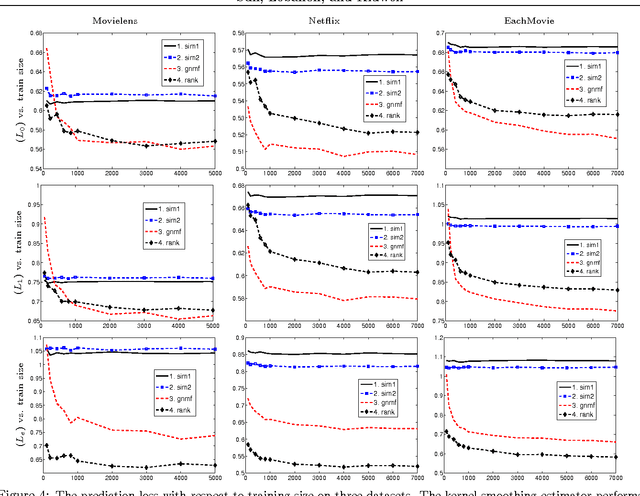
Recommendation systems are emerging as an important business application with significant economic impact. Currently popular systems include Amazon's book recommendations, Netflix's movie recommendations, and Pandora's music recommendations. In this paper we address the problem of estimating probabilities associated with recommendation system data using non-parametric kernel smoothing. In our estimation we interpret missing items as randomly censored observations and obtain efficient computation schemes using combinatorial properties of generating functions. We demonstrate our approach with several case studies involving real world movie recommendation data. The results are comparable with state-of-the-art techniques while also providing probabilistic preference estimates outside the scope of traditional recommender systems.