 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetric and Kernel Learning using a Linear Transformation
Paper and Code
Oct 30, 2009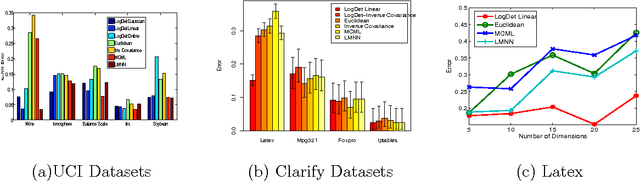

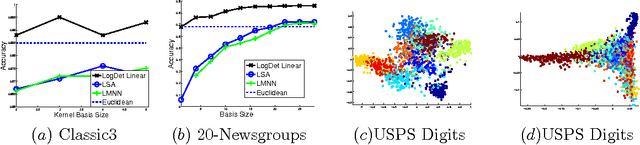
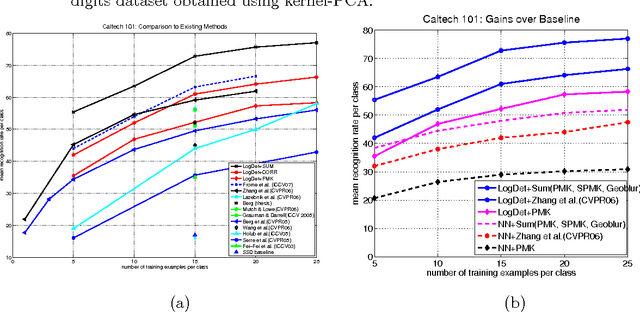
Metric and kernel learning are important in several machine learning applications. However, most existing metric learning algorithms are limited to learning metrics over low-dimensional data, while existing kernel learning algorithms are often limited to the transductive setting and do not generalize to new data points. In this paper, we study metric learning as a problem of learning a linear transformation of the input data. We show that for high-dimensional data, a particular framework for learning a linear transformation of the data based on the LogDet divergence can be efficiently kernelized to learn a metric (or equivalently, a kernel function) over an arbitrarily high dimensional space. We further demonstrate that a wide class of convex loss functions for learning linear transformations can similarly be kernelized, thereby considerably expanding the potential applications of metric learning. We demonstrate our learning approach by applying it to large-scale real world problems in computer vision and text mining.