 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForest Garrote
Paper and Code
Jun 19, 2009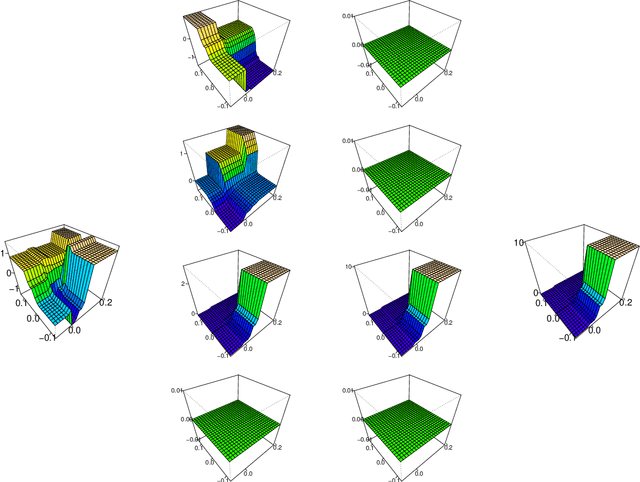
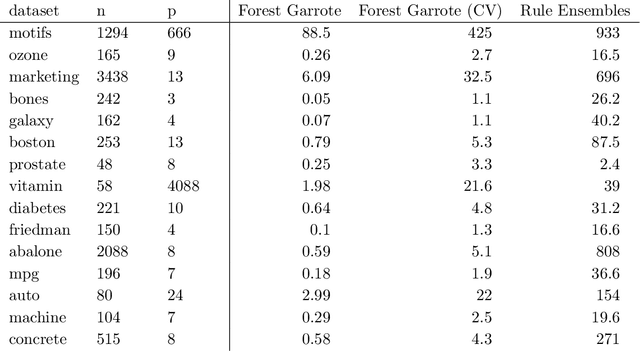
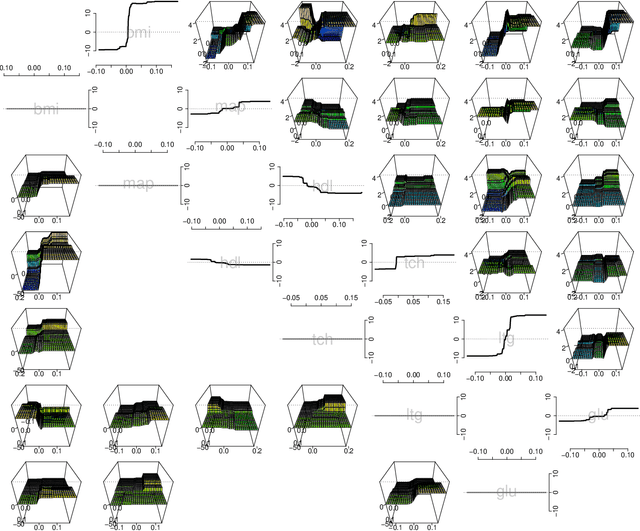
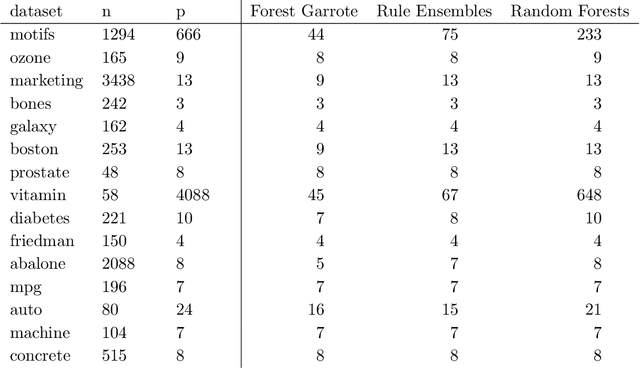
Variable selection for high-dimensional linear models has received a lot of attention lately, mostly in the context of l1-regularization. Part of the attraction is the variable selection effect: parsimonious models are obtained, which are very suitable for interpretation. In terms of predictive power, however, these regularized linear models are often slightly inferior to machine learning procedures like tree ensembles. Tree ensembles, on the other hand, lack usually a formal way of variable selection and are difficult to visualize. A Garrote-style convex penalty for trees ensembles, in particular Random Forests, is proposed. The penalty selects functional groups of nodes in the trees. These could be as simple as monotone functions of individual predictor variables. This yields a parsimonious function fit, which lends itself easily to visualization and interpretation. The predictive power is maintained at least at the same level as the original tree ensemble. A key feature of the method is that, once a tree ensemble is fitted, no further tuning parameter needs to be selected. The empirical performance is demonstrated on a wide array of datasets.