 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP-values for high-dimensional regression
Paper and Code
Jun 12, 2009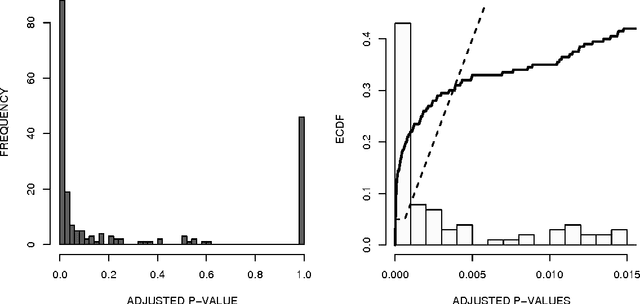
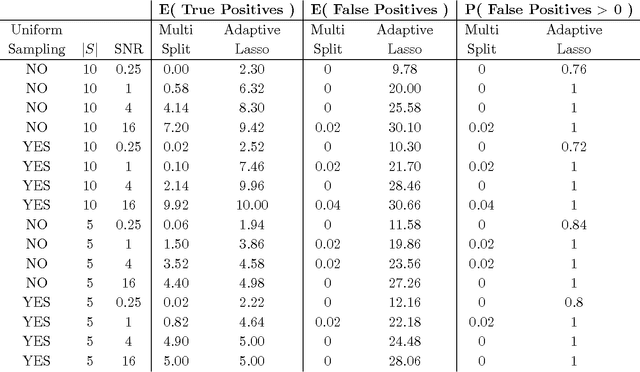
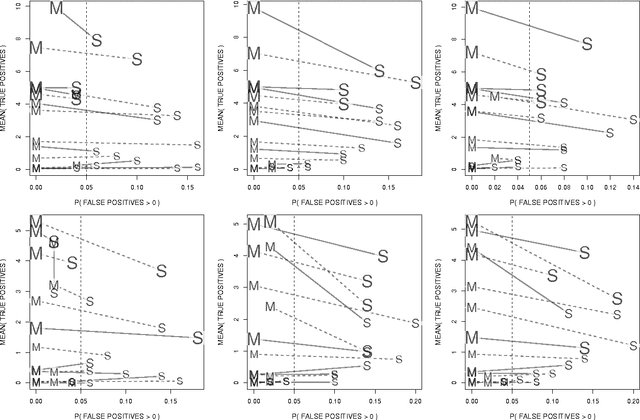
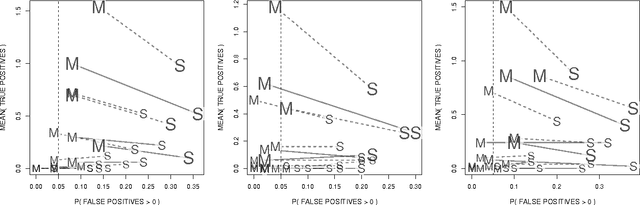
Assigning significance in high-dimensional regression is challenging. Most computationally efficient selection algorithms cannot guard against inclusion of noise variables. Asymptotically valid p-values are not available. An exception is a recent proposal by Wasserman and Roeder (2008) which splits the data into two parts. The number of variables is then reduced to a manageable size using the first split, while classical variable selection techniques can be applied to the remaining variables, using the data from the second split. This yields asymptotic error control under minimal conditions. It involves, however, a one-time random split of the data. Results are sensitive to this arbitrary choice: it amounts to a `p-value lottery' and makes it difficult to reproduce results. Here, we show that inference across multiple random splits can be aggregated, while keeping asymptotic control over the inclusion of noise variables. We show that the resulting p-values can be used for control of both family-wise error (FWER) and false discovery rate (FDR). In addition, the proposed aggregation is shown to improve power while reducing the number of falsely selected variables substantially.