 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample Selection Bias Correction Theory
Paper and Code
May 19, 2008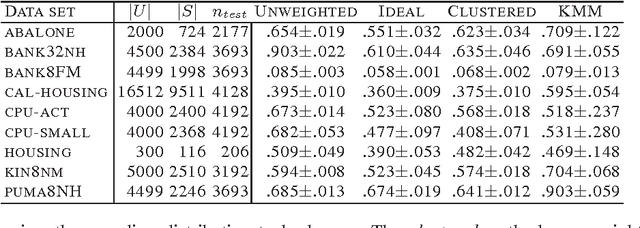
This paper presents a theoretical analysis of sample selection bias correction. The sample bias correction technique commonly used in machine learning consists of reweighting the cost of an error on each training point of a biased sample to more closely reflect the unbiased distribution. This relies on weights derived by various estimation techniques based on finite samples. We analyze the effect of an error in that estimation on the accuracy of the hypothesis returned by the learning algorithm for two estimation techniques: a cluster-based estimation technique and kernel mean matching. We also report the results of sample bias correction experiments with several data sets using these techniques. Our analysis is based on the novel concept of distributional stability which generalizes the existing concept of point-based stability. Much of our work and proof techniques can be used to analyze other importance weighting techniques and their effect on accuracy when using a distributionally stable algorithm.