 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of French Phonetic Idiosyncrasies for Accent Recognition
Paper and Code
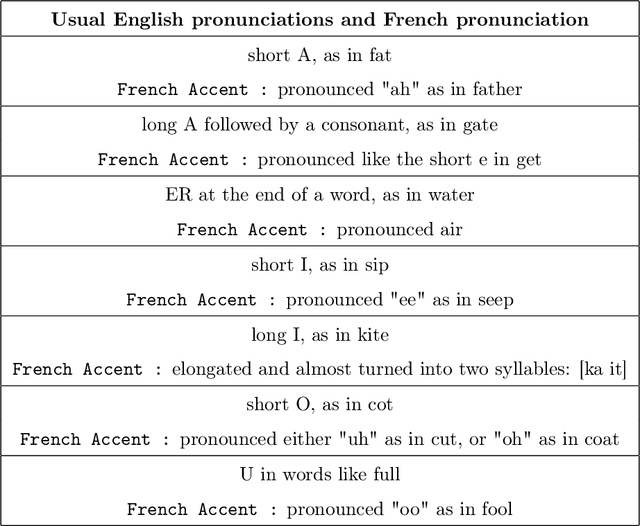
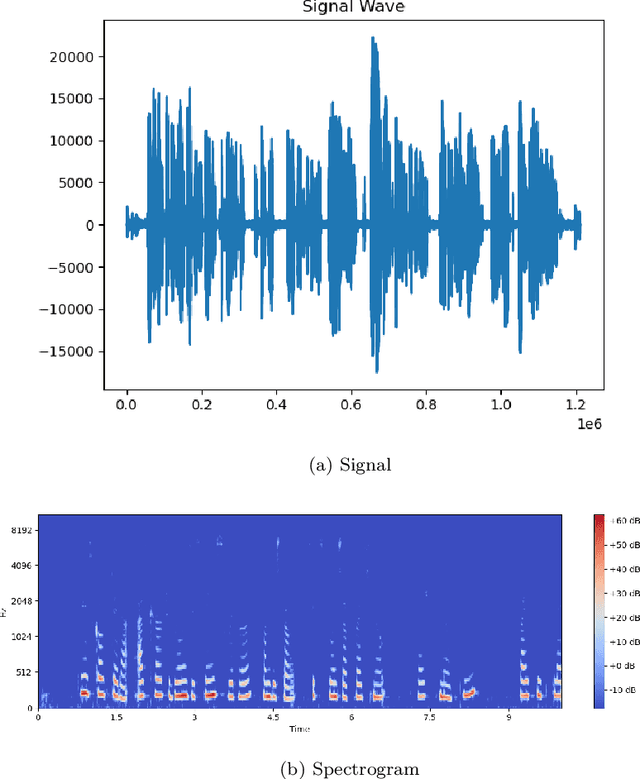
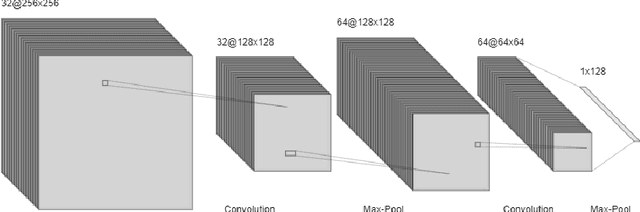
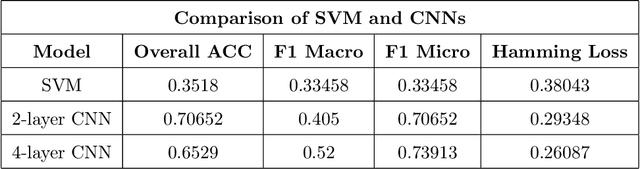
Speech recognition systems have made tremendous progress since the last few decades. They have developed significantly in identifying the speech of the speaker. However, there is a scope of improvement in speech recognition systems in identifying the nuances and accents of a speaker. It is known that any specific natural language may possess at least one accent. Despite the identical word phonemic composition, if it is pronounced in different accents, we will have sound waves, which are different from each other. Differences in pronunciation, in accent and intonation of speech in general, create one of the most common problems of speech recognition. If there are a lot of accents in language we should create the acoustic model for each separately. We carry out a systematic analysis of the problem in the accurate classification of accents. We use traditional machine learning techniques and convolutional neural networks, and show that the classical techniques are not sufficiently efficient to solve this problem. Using spectrograms of speech signals, we propose a multi-class classification framework for accent recognition. In this paper, we focus our attention on the French accent. We also identify its limitation by understanding the impact of French idiosyncrasies on its spectrograms.