Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hybrid Approach for Reinforcement Learning Using Virtual Policy Gradient for Balancing an Inverted Pendulum
Paper and Code
Feb 06, 2021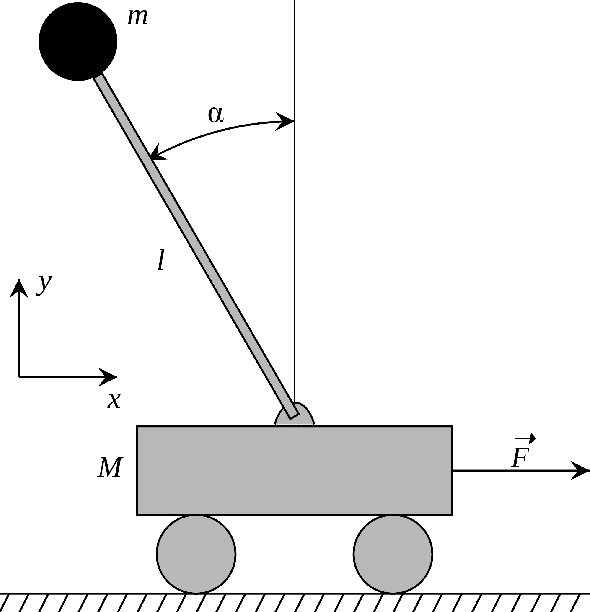

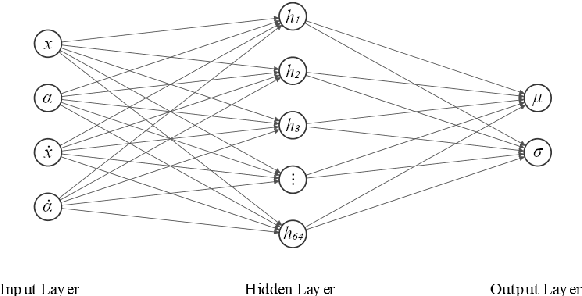
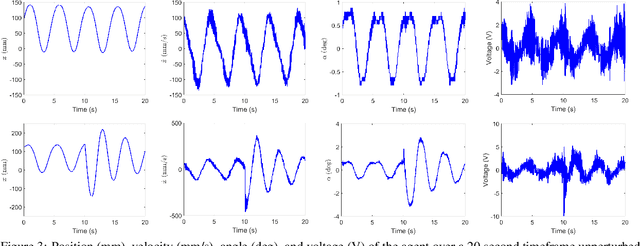
Using the policy gradient algorithm, we train a single-hidden-layer neural network to balance a physically accurate simulation of a single inverted pendulum. The trained weights and biases can then be transferred to a physical agent, where they are robust enough to to balance a real inverted pendulum. This hybrid approach of training a simulation allows thousands of trial runs to be completed orders of magnitude faster than would be possible in the real world, resulting in greatly reduced training time and more iterations, producing a more robust model. When compared with existing reinforcement learning methods, the resulting control is smoother, learned faster, and able to withstand forced disturbances.
* ICAART '21: Proceedings of the 13th International Conference on
Agents and Artificial Intelligence, Doctoral Consortium, 2021. 9 pages, 3
figures
View paper on