 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey On Anti-Spoofing Methods For Face Recognition with RGB Cameras of Generic Consumer Devices
Oct 08, 2020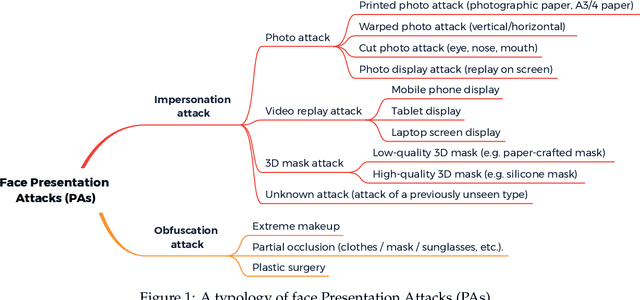
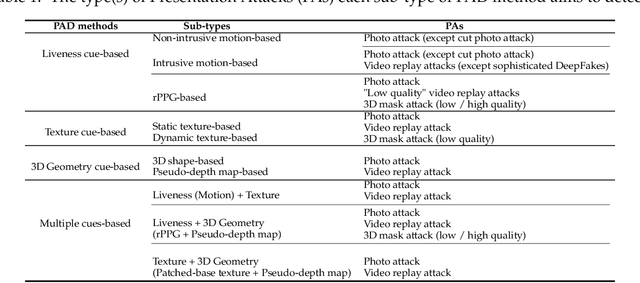

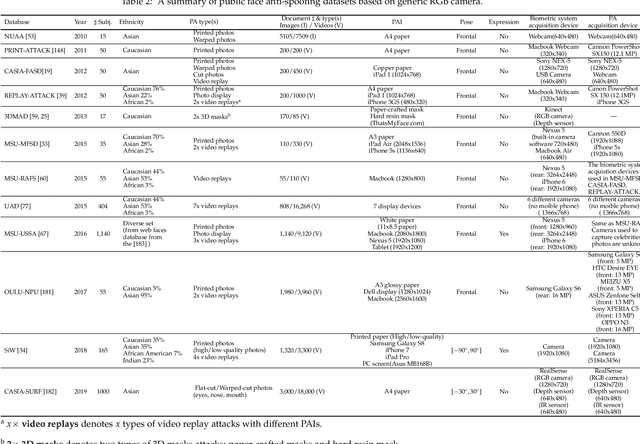
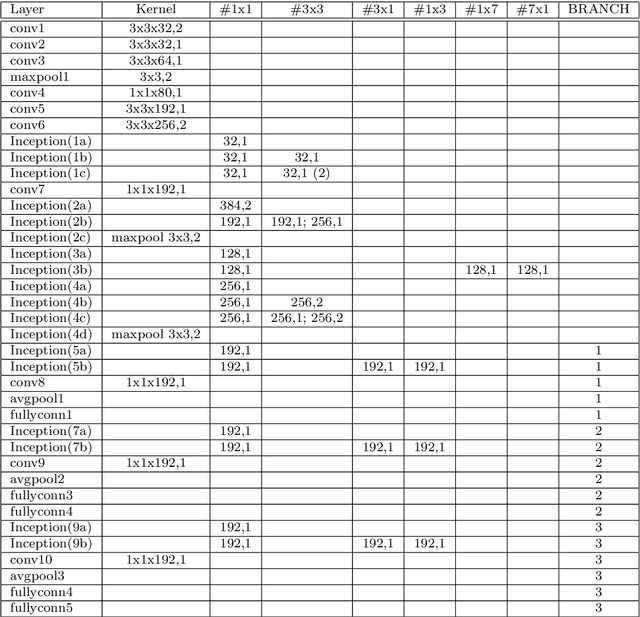
The widespread deployment of face recognition-based biometric systems has made face Presentation Attack Detection (face anti-spoofing) an increasingly critical issue. This survey thoroughly investigates the face Presentation Attack Detection (PAD) methods, that only require RGB cameras of generic consumer devices, over the past two decades. We present an attack scenario-oriented typology of the existing face PAD methods and we provide a review of over 50 of the most recent face PAD methods and their related issues. We adopt a comprehensive presentation of the methods that have most influenced face PAD following the proposed typology, and in chronological order. By doing so, we depict the main challenges, evolutions and current trends in the field of face PAD, and provide insights on its future research. From an experimental point of view, this survey paper provides a summarized overview of the available public databases and extensive comparative experimental results of different PAD methods.
Cross-modal Multi-task Learning for Graphic Recognition of Caricature Face
Mar 10, 2020
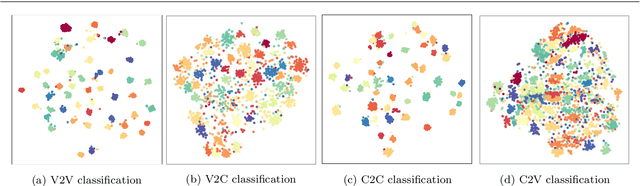
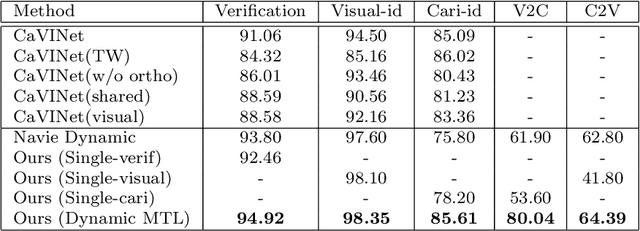
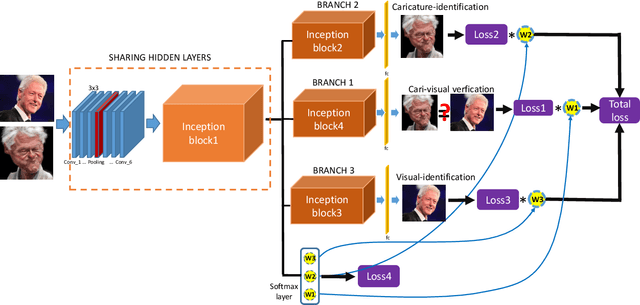
Face recognition of realistic visual images has been well studied and made a significant progress in the recent decade. Unlike the realistic visual images, the face recognition of the caricatures is far from the performance of the visual images. This is largely due to the extreme non-rigid distortions of the caricatures introduced by exaggerating the facial features to strengthen the characters. The heterogeneous modalities of the caricatures and the visual images result the caricature-visual face recognition is a cross-modal problem. In this paper, we propose a method to conduct caricature-visual face recognition via multi-task learning. Rather than the conventional multi-task learning with fixed weights of tasks, this work proposes an approach to learn the weights of tasks according to the importance of tasks. The proposed multi-task learning with dynamic tasks weights enables to appropriately train the hard task and easy task instead of being stuck in the over-training easy task as conventional methods. The experimental results demonstrate the effectiveness of the proposed dynamic multi-task learning for cross-modal caricature-visual face recognition. The performances on the datasets CaVI and WebCaricature show the superiority over the state-of-art methods.
Face Detection in Camera Captured Images of Identity Documents under Challenging Conditions
Nov 08, 2019
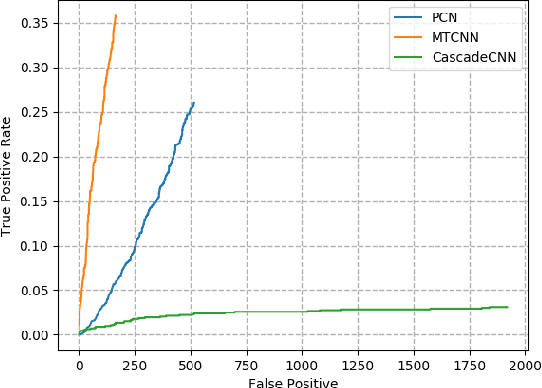


Benefiting from the advance of deep convolutional neural network approaches (CNNs), many face detection algorithms have achieved state-of-the-art performance in terms of accuracy and very high speed in unconstrained applications. However, due to the lack of public datasets and due to the variation of the orientation of face images, the complex background and lighting, defocus and the varying illumination of camera captured images, face detection on identity documents under unconstrained environments has not been sufficiently studied. To address this problem more efficiently, we survey three state-of-the-art face detection methods based on general images, i.e. Cascade-CNN, MTCNN and PCN, for face detection in camera captured images of identity documents, given different image quality assessments. For that, The MIDV-500 dataset, which is the largest and most challenging dataset for identity documents, is used to evaluate the three methods. The evaluation results show the performance and the limitations of the current methods for face detection on identity documents under the wild complex environments. These results show that the face detection task in camera captured images of identity documents is challenging, providing a space to improve in the future works.
Dynamic Deep Multi-task Learning for Caricature-Visual Face Recognition
Nov 08, 2019
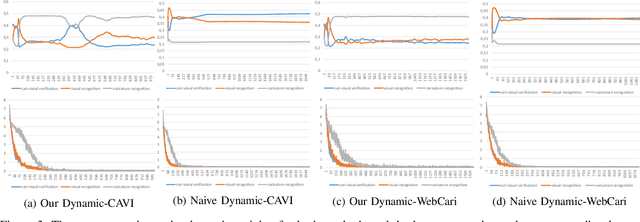
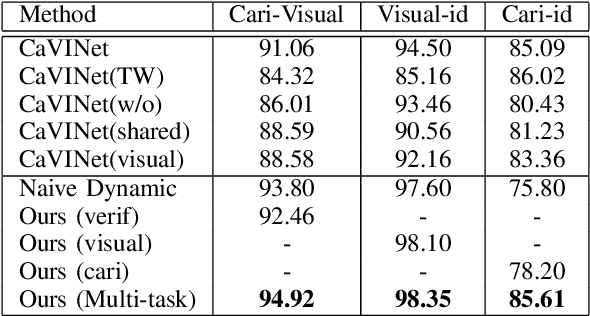
Rather than the visual images, the face recognition of the caricatures is far from the performance of the visual images. The challenge is the extreme non-rigid distortions of the caricatures introduced by exaggerating the facial features to strengthen the characters. In this paper, we propose dynamic multi-task learning based on deep CNNs for cross-modal caricature-visual face recognition. Instead of the conventional multi-task learning with fixed weights of the tasks, the proposed dynamic multi-task learning dynamically updates the weights of tasks according to the importance of the tasks, which enables the training of the networks focus on the hard task instead of being stuck in the overtraining of the easy task. The experimental results demonstrate the effectiveness of the dynamic multi-task learning for caricature-visual face recognition. The performance evaluated on the datasets CaVI and WebCaricature show the superiority over the state-of-art methods. The implementation code is available here.
Dynamic Multi-Task Learning for Face Recognition with Facial Expression
Nov 08, 2019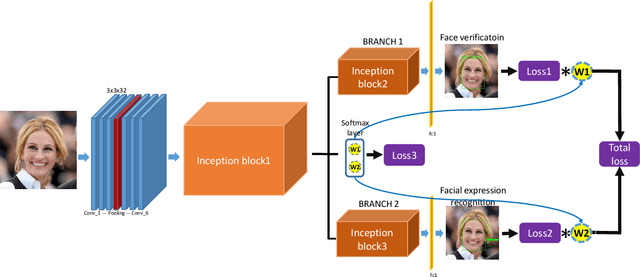

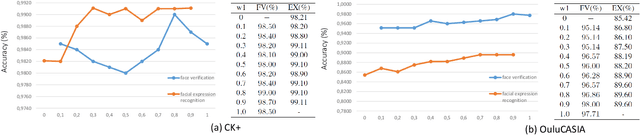
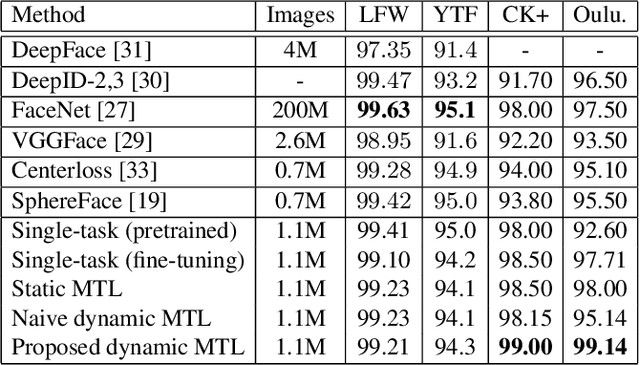
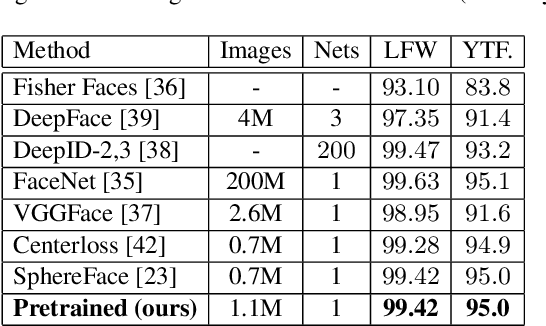
Benefiting from the joint learning of the multiple tasks in the deep multi-task networks, many applications have shown the promising performance comparing to single-task learning. However, the performance of multi-task learning framework is highly dependant on the relative weights of the tasks. How to assign the weight of each task is a critical issue in the multi-task learning. Instead of tuning the weights manually which is exhausted and time-consuming, in this paper we propose an approach which can dynamically adapt the weights of the tasks according to the difficulty for training the task. Specifically, the proposed method does not introduce the hyperparameters and the simple structure allows the other multi-task deep learning networks can easily realize or reproduce this method. We demonstrate our approach for face recognition with facial expression and facial expression recognition from a single input image based on a deep multi-task learning Conventional Neural Networks (CNNs). Both the theoretical analysis and the experimental results demonstrate the effectiveness of the proposed dynamic multi-task learning method. This multi-task learning with dynamic weights also boosts of the performance on the different tasks comparing to the state-of-art methods with single-task learning.
FaceLiveNet+: A Holistic Networks For Face Authentication Based On Dynamic Multi-task Convolutional Neural Networks
Feb 28, 2019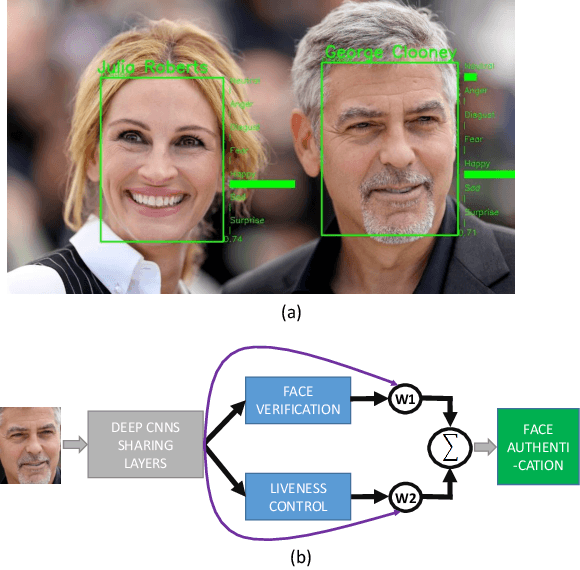

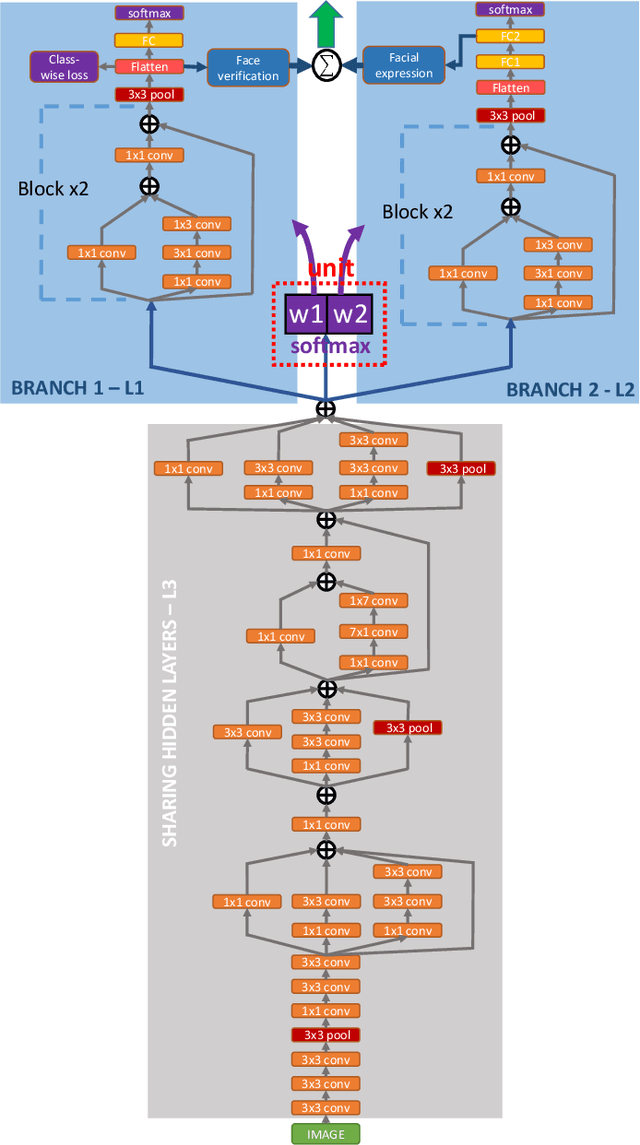
This paper proposes a holistic multi-task Convolutional Neural Networks (CNNs) with the dynamic weights of the tasks,namely FaceLiveNet+, for face authentication. FaceLiveNet+ can employ face verification and facial expression recognition as a solution of liveness control simultaneously. Comparing to the single-task learning, the proposed multi-task learning can better capture the feature representation for all of the tasks. The experimental results show the superiority of the multi-task learning to the single-task learning for both the face verification task and facial expression recognition task. Rather using a conventional multi-task learning with fixed weights for the tasks, this work proposes a so called dynamic-weight-unit to automatically learn the weights of the tasks. The experiments have shown the effectiveness of the dynamic weights for training the networks. Finally, the holistic evaluation for face authentication based on the proposed protocol has shown the feasibility to apply the FaceLiveNet+ for face authentication.