 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRW-Resnet: A Novel Speech Anti-Spoofing Model Using Raw Waveform
Aug 13, 2021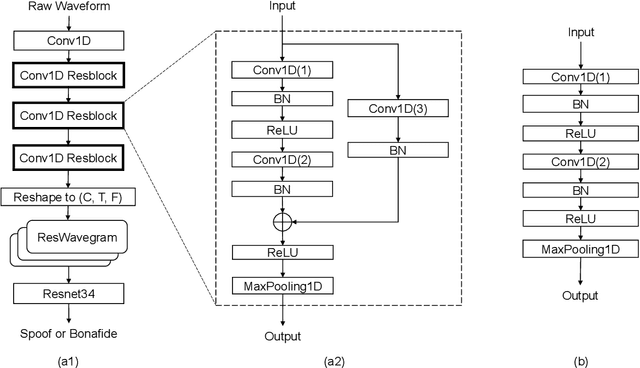
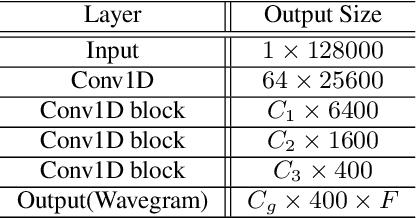
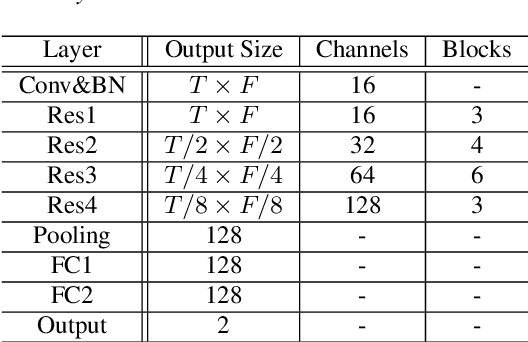
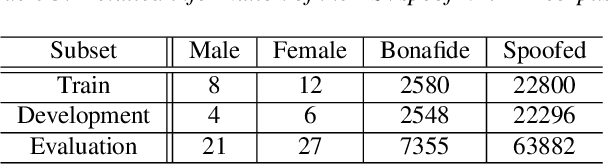
In recent years, synthetic speech generated by advanced text-to-speech (TTS) and voice conversion (VC) systems has caused great harms to automatic speaker verification (ASV) systems, urging us to design a synthetic speech detection system to protect ASV systems. In this paper, we propose a new speech anti-spoofing model named ResWavegram-Resnet (RW-Resnet). The model contains two parts, Conv1D Resblocks and backbone Resnet34. The Conv1D Resblock is based on the Conv1D block with a residual connection. For the first part, we use the raw waveform as input and feed it to the stacked Conv1D Resblocks to get the ResWavegram. Compared with traditional methods, ResWavegram keeps all the information from the audio signal and has a stronger ability in extracting features. For the second part, the extracted features are fed to the backbone Resnet34 for the spoofed or bonafide decision. The ASVspoof2019 logical access (LA) corpus is used to evaluate our proposed RW-Resnet. Experimental results show that the RW-Resnet achieves better performance than other state-of-the-art anti-spoofing models, which illustrates its effectiveness in detecting synthetic speech attacks.
A Study on Angular Based Embedding Learning for Text-independent Speaker Verification
Aug 12, 2019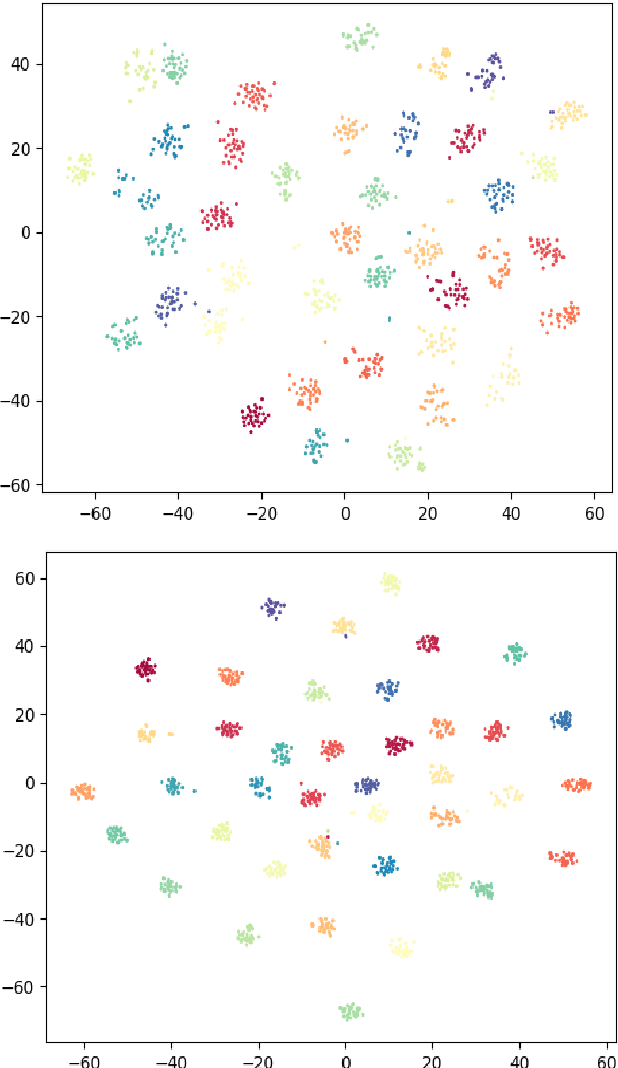
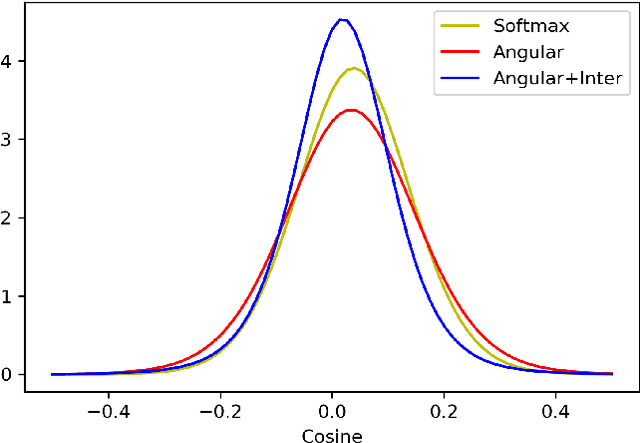
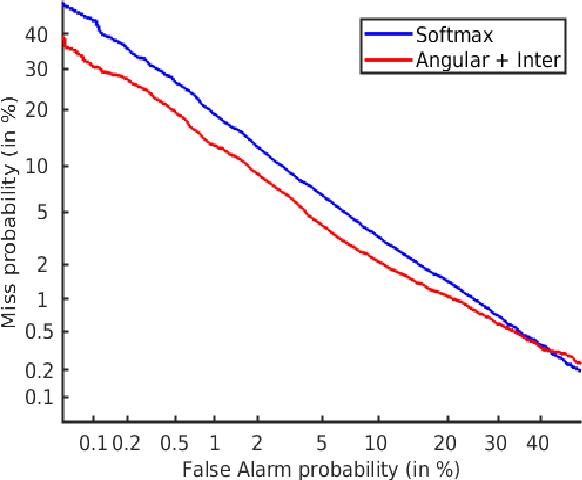
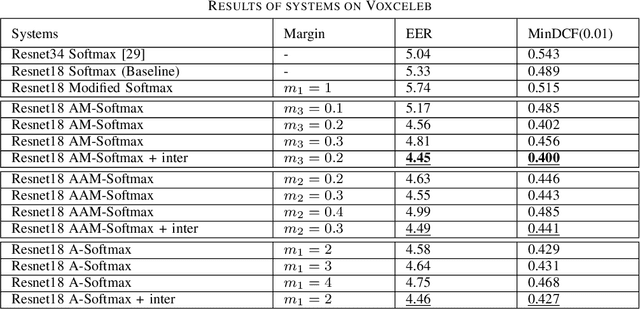
Learning a good speaker embedding is important for many automatic speaker recognition tasks, including verification, identification and diarization. The embeddings learned by softmax are not discriminative enough for open-set verification tasks. Angular based embedding learning target can achieve such discriminativeness by optimizing angular distance and adding margin penalty. We apply several different popular angular margin embedding learning strategies in this work and explicitly compare their performance on Voxceleb speaker recognition dataset. Observing the fact that encouraging inter-class separability is important when applying angular based embedding learning, we propose an exclusive inter-class regularization as a complement for angular based loss. We verify the effectiveness of these methods for learning a discriminative embedding space on ASV task with several experiments. These methods together, we manage to achieve an impressive result with 16.5% improvement on equal error rate (EER) and 18.2% improvement on minimum detection cost function comparing with baseline softmax systems.
Two-stage Training for Chinese Dialect Recognition
Aug 10, 2019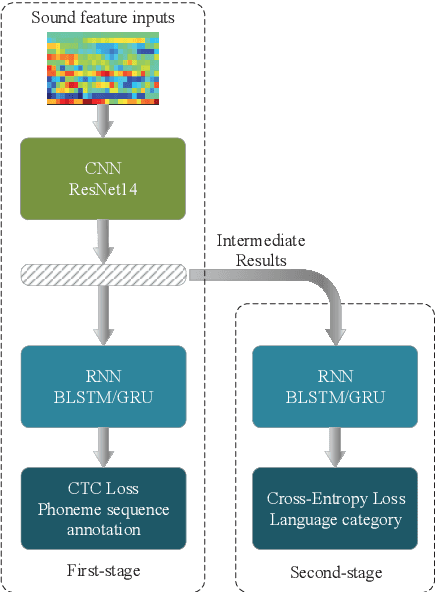
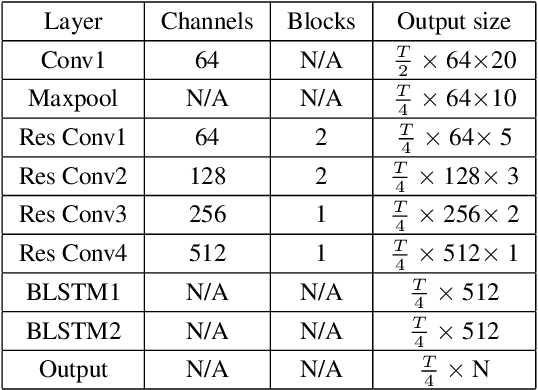
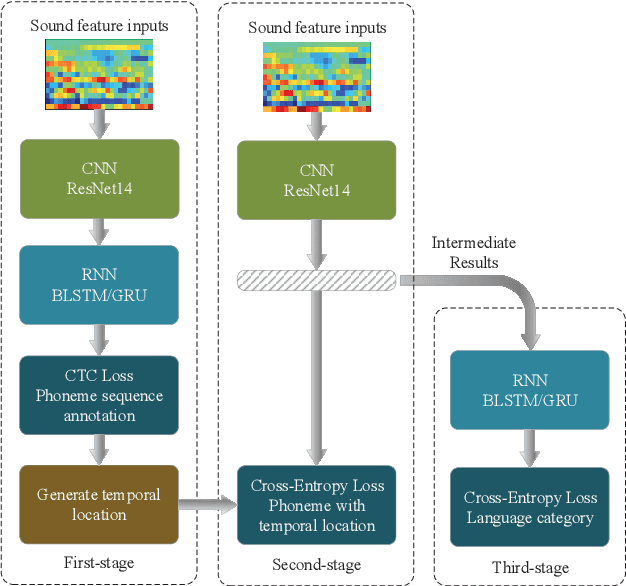
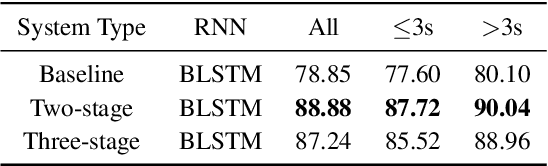
In this paper, we present a two-stage language identification (LID) system based on a shallow ResNet14 followed by a simple 2-layer recurrent neural network (RNN) architecture, which was used for Xunfei (iFlyTek) Chinese Dialect Recognition Challenge and won the first place among 110 teams. The system trains an acoustic model (AM) firstly with connectionist temporal classification (CTC) to recognize the given phonetic sequence annotation and then train another RNN to classify dialect category by utilizing the intermediate features as inputs from the AM. Compared with a three-stage system we further explore, our results show that the two-stage system can achieve high accuracy for Chinese dialects recognition under both short utterance and long utterance conditions with less training time.
Triplet Based Embedding Distance and Similarity Learning for Text-independent Speaker Verification
Aug 06, 2019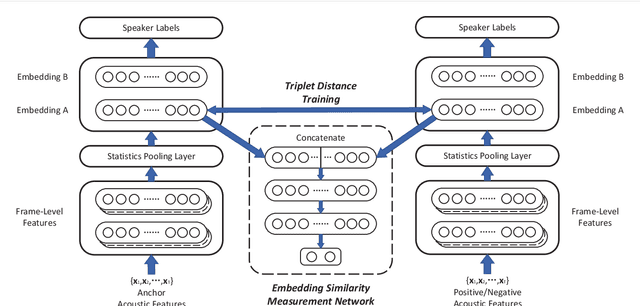
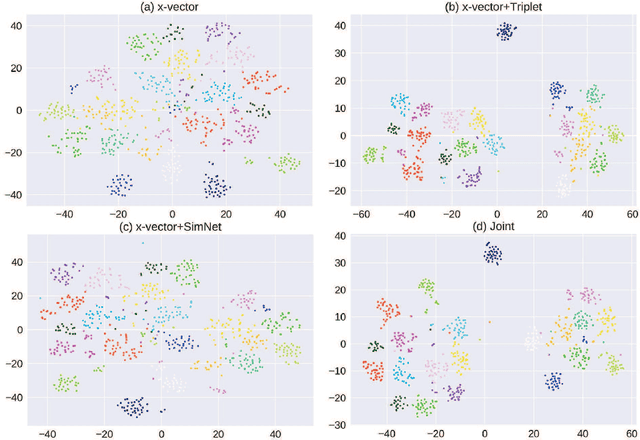
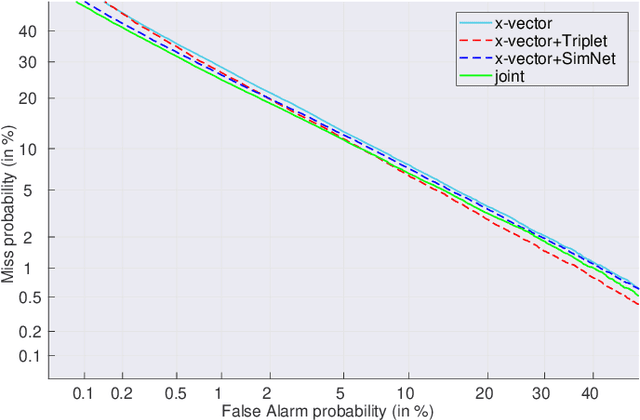
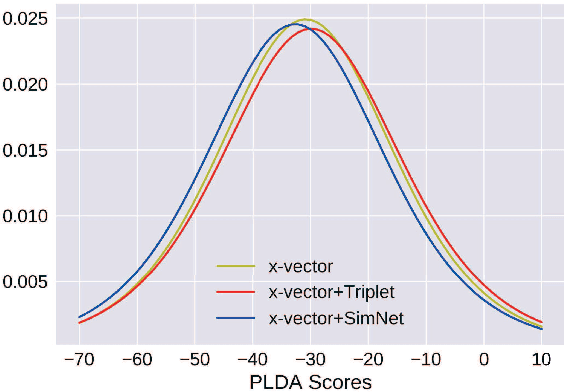
Speaker embeddings become growing popular in the text-independent speaker verification task. In this paper, we propose two improvements during the training stage. The improvements are both based on triplet cause the training stage and the evaluation stage of the baseline x-vector system focus on different aims. Firstly, we introduce triplet loss for optimizing the Euclidean distances between embeddings while minimizing the multi-class cross entropy loss. Secondly, we design an embedding similarity measurement network for controlling the similarity between the two selected embeddings. We further jointly train the two new methods with the original network and achieve state-of-the-art. The multi-task training synergies are shown with a 9% reduction equal error rate (EER) and detected cost function (DCF) on the 2016 NIST Speaker Recognition Evaluation (SRE) Test Set.