 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuromorphic Reinforcement Learning for Quadruped Locomotion Control on Uneven Terrain
May 10, 2026Reinforcement learning (RL) has enabled robust quadruped locomotion over complex terrain, but most learned controllers are trained offline with backpropagation in massively parallel simulation and deployed as fixed policies, limiting adaptation to terrain variation, payload changes, actuator wear, and other real-world conditions under onboard power constraints. Local learning provides a potential path toward energy-aware on-robot adaptation by replacing global backpropagation graphs with updates driven by local neural states, making the learning rule more compatible with neuromorphic and in-memory computing substrates. This work proposes an equilibrium-propagation (EP)-based proximal policy optimization (PPO) framework for uneven-terrain quadruped locomotion. The controller combines a bio-inspired central pattern generator (CPG) policy with a residual postural adjustment policy, while replacing conventional backpropagation-trained policy and value networks with EP-enabled local learning. To train stochastic continuous-control policies with EP, we derive an EP-compatible PPO output-nudging signal and introduce a two-sided ratio clipping mechanism that stabilizes policy updates during relaxation. Experiments on a 12-DoF A1 quadruped show that the proposed controller achieves stable policy convergence in a two-stage uneven terrain locomotion task. Its locomotion performance is comparable to a backpropagation-trained PPO baseline in success rate, velocity tracking, actuator power, and body stability, while improving GPU memory efficiency by 4.3\(\times\) compared with backpropagation through time (BPTT). These results suggest that local equilibrium-based learning can support high-dimensional embodied locomotion and provide an algorithmic foundation for low-power on-robot adaptation and fine-tuning.
Astrocyte Regulated Neuromorphic Central Pattern Generator Control of Legged Robotic Locomotion
Jan 05, 2024Neuromorphic computing systems, where information is transmitted through action potentials in a bio-plausible fashion, is gaining increasing interest due to its promise of low-power event-driven computing. Application of neuromorphic computing in robotic locomotion research have largely focused on Central Pattern Generators (CPGs) for bionics robotic control algorithms - inspired from neural circuits governing the collaboration of the limb muscles in animal movement. Implementation of artificial CPGs on neuromorphic hardware platforms can potentially enable adaptive and energy-efficient edge robotics applications in resource constrained environments. However, underlying rewiring mechanisms in CPG for gait emergence process is not well understood. This work addresses the missing gap in literature pertaining to CPG plasticity and underscores the critical homeostatic functionality of astrocytes - a cellular component in the brain that is believed to play a major role in multiple brain functions. This paper introduces an astrocyte regulated Spiking Neural Network (SNN)-based CPG for learning locomotion gait through Reward-Modulated STDP for quadruped robots, where the astrocytes help build inhibitory connections among the artificial motor neurons in different limbs. The SNN-based CPG is simulated on a multi-object physics simulation platform resulting in the emergence of a trotting gait while running the robot on flat ground. $23.3\times$ computational power savings is observed in comparison to a state-of-the-art reinforcement learning based robot control algorithm. Such a neuroscience-algorithm co-design approach can potentially enable a quantum leap in the functionality of neuromorphic systems incorporating glial cell functionality.
Astromorphic Self-Repair of Neuromorphic Hardware Systems
Sep 15, 2022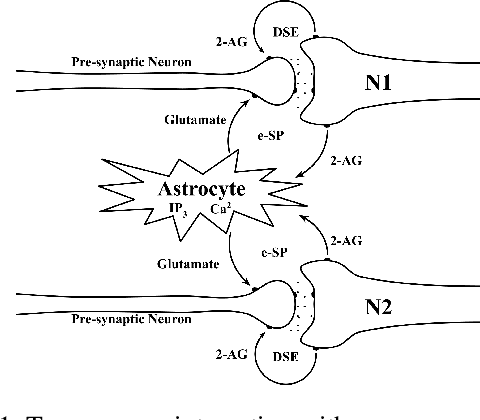
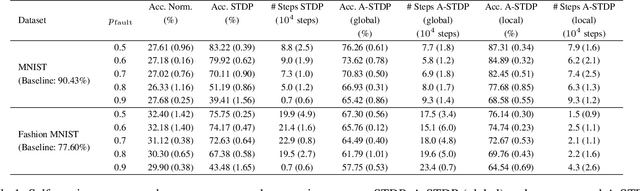
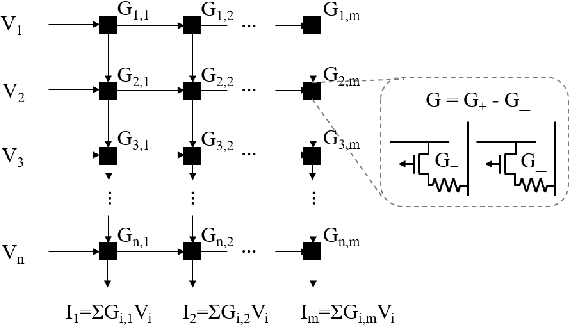
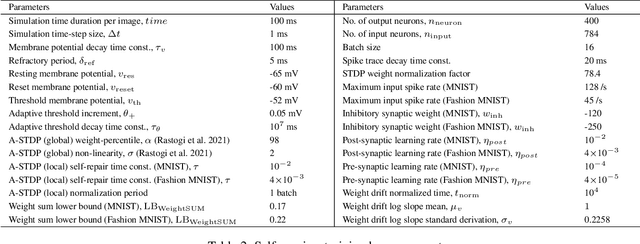
While neuromorphic computing architectures based on Spiking Neural Networks (SNNs) are increasingly gaining interest as a pathway toward bio-plausible machine learning, attention is still focused on computational units like the neuron and synapse. Shifting from this neuro-synaptic perspective, this paper attempts to explore the self-repair role of glial cells, in particular, astrocytes. The work investigates stronger correlations with astrocyte computational neuroscience models to develop macro-models with a higher degree of bio-fidelity that accurately captures the dynamic behavior of the self-repair process. Hardware-software co-design analysis reveals that bio-morphic astrocytic regulation has the potential to self-repair hardware realistic faults in neuromorphic hardware systems with significantly better accuracy and repair convergence for unsupervised learning tasks on the MNIST and F-MNIST datasets.