 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynchronous Transformers for End-to-End Speech Recognition
Dec 06, 2019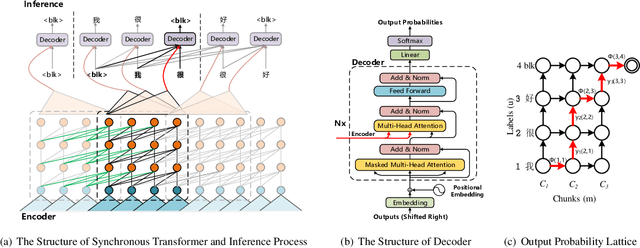
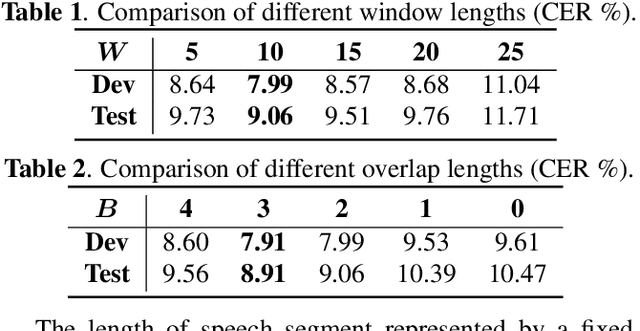

For most of the attention-based sequence-to-sequence models, the decoder predicts the output sequence conditioned on the entire input sequence processed by the encoder. The asynchronous problem between the encoding and decoding makes these models difficult to be applied for online speech recognition. In this paper, we propose a model named synchronous transformer to address this problem, which can predict the output sequence chunk by chunk. Once a fixed-length chunk of the input sequence is processed by the encoder, the decoder begins to predict symbols immediately. During training, a forward-backward algorithm is introduced to optimize all the possible alignment paths. Our model is evaluated on a Mandarin dataset AISHELL-1. The experiments show that the synchronous transformer is able to perform encoding and decoding synchronously, and achieves a character error rate of 8.91% on the test set.
Integrating Whole Context to Sequence-to-sequence Speech Recognition
Dec 04, 2019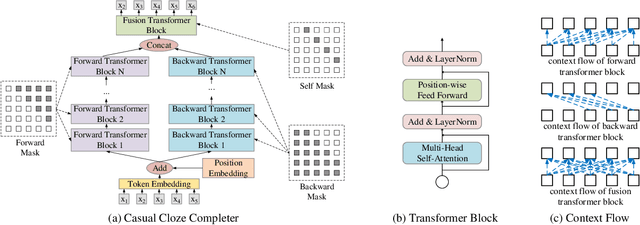
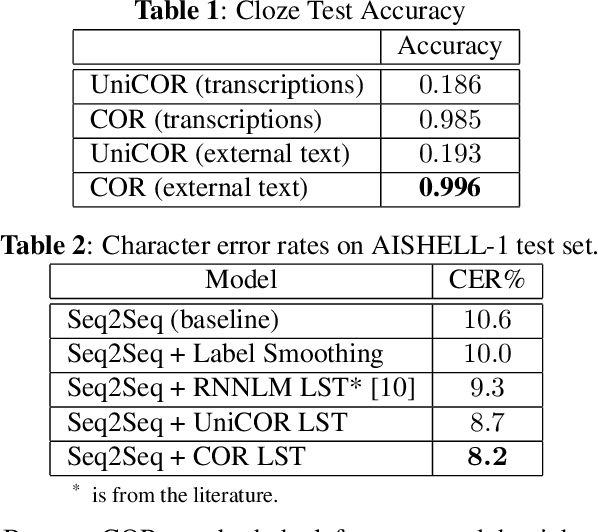
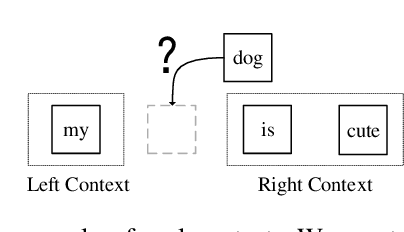
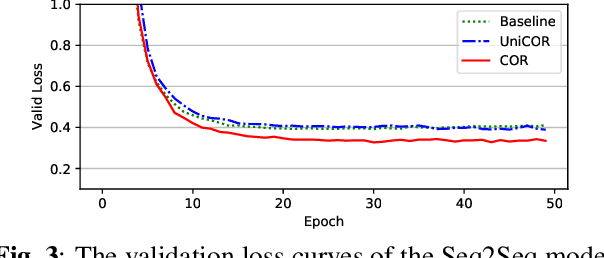
Because an attention based sequence-to-sequence speech (Seq2Seq) recognition model decodes a token sequence in a left-to-right manner, it is non-trivial for the decoder to leverage the whole context of the target sequence. In this paper, we propose a self-attention mechanism based language model called casual cloze completer (COR), which models the left context and the right context simultaneously. Then, we utilize our previously proposed "Learn Spelling from Teachers" approach to integrate the whole context knowledge from COR to the Seq2Seq model. We conduct the experiments on public Chinese dataset AISHELL-1. The experimental results show that leveraging whole context can improve the performance of the Seq2Seq model.
Self-Attention Transducers for End-to-End Speech Recognition
Sep 28, 2019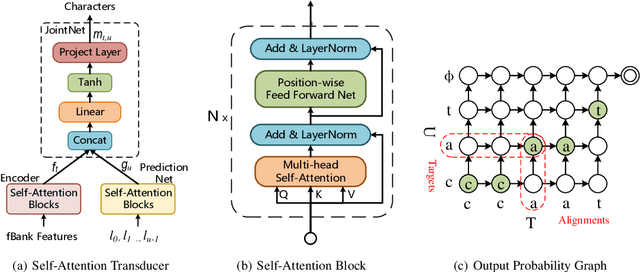
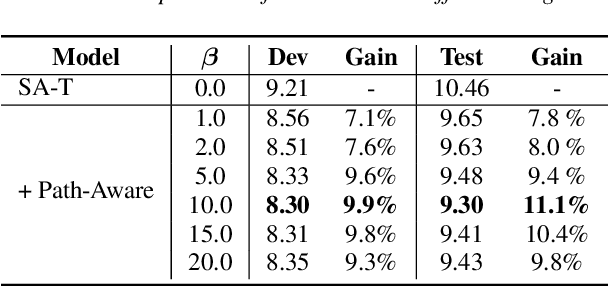
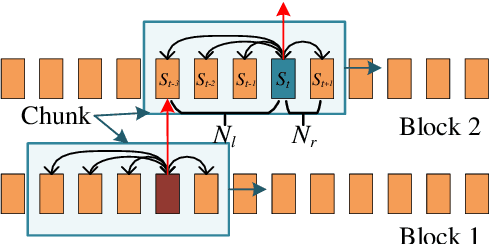
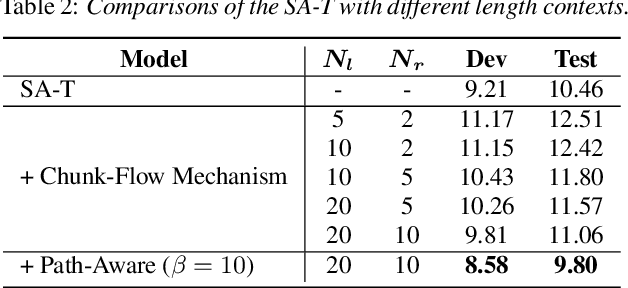
Recurrent neural network transducers (RNN-T) have been successfully applied in end-to-end speech recognition. However, the recurrent structure makes it difficult for parallelization . In this paper, we propose a self-attention transducer (SA-T) for speech recognition. RNNs are replaced with self-attention blocks, which are powerful to model long-term dependencies inside sequences and able to be efficiently parallelized. Furthermore, a path-aware regularization is proposed to assist SA-T to learn alignments and improve the performance. Additionally, a chunk-flow mechanism is utilized to achieve online decoding. All experiments are conducted on a Mandarin Chinese dataset AISHELL-1. The results demonstrate that our proposed approach achieves a 21.3% relative reduction in character error rate compared with the baseline RNN-T. In addition, the SA-T with chunk-flow mechanism can perform online decoding with only a little degradation of the performance.
Learn Spelling from Teachers: Transferring Knowledge from Language Models to Sequence-to-Sequence Speech Recognition
Jul 13, 2019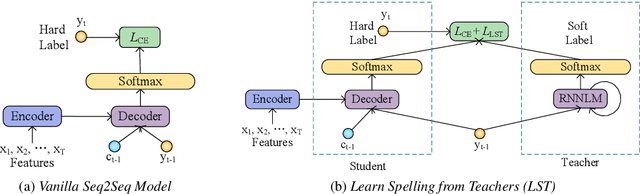
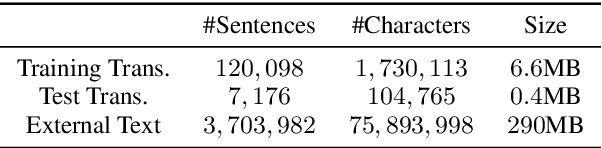
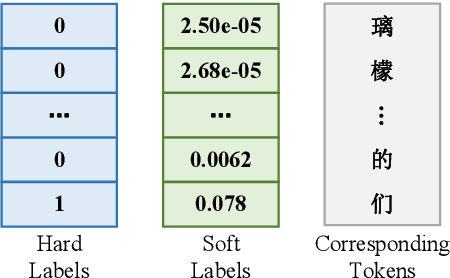

Integrating an external language model into a sequence-to-sequence speech recognition system is non-trivial. Previous works utilize linear interpolation or a fusion network to integrate external language models. However, these approaches introduce external components, and increase decoding computation. In this paper, we instead propose a knowledge distillation based training approach to integrating external language models into a sequence-to-sequence model. A recurrent neural network language model, which is trained on large scale external text, generates soft labels to guide the sequence-to-sequence model training. Thus, the language model plays the role of the teacher. This approach does not add any external component to the sequence-to-sequence model during testing. And this approach is flexible to be combined with shallow fusion technique together for decoding. The experiments are conducted on public Chinese datasets AISHELL-1 and CLMAD. Our approach achieves a character error rate of 9.3%, which is relatively reduced by 18.42% compared with the vanilla sequence-to-sequence model.