 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Known Information to Accelerate HyperParameters Optimization Based on SMBO
Nov 08, 2018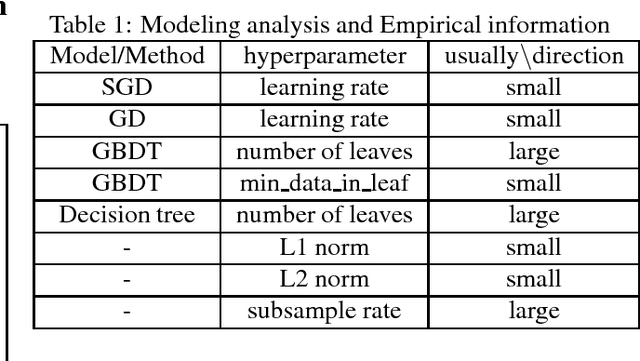
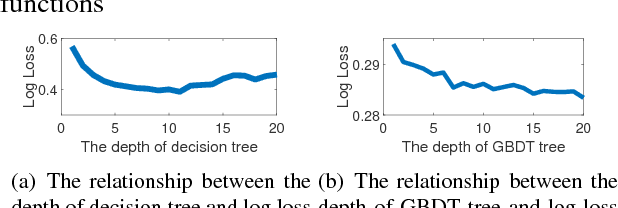
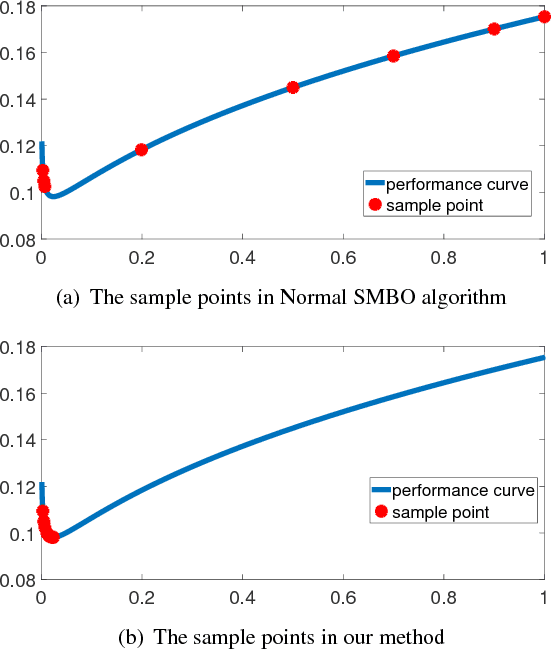
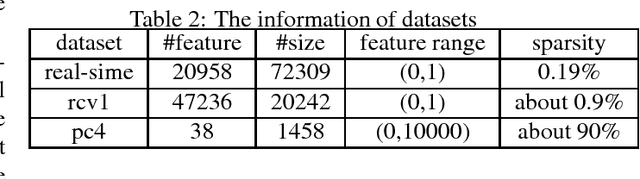
Automl is the key technology for machine learning problem. Current state of art hyperparameter optimization methods are based on traditional black-box optimization methods like SMBO (SMAC, TPE). The objective function of black-box optimization is non-smooth, or time-consuming to evaluate, or in some way noisy. Recent years, many researchers offered the work about the properties of hyperparameters. However, traditional hyperparameter optimization methods do not take those information into consideration. In this paper, we use gradient information and machine learning model analysis information to accelerate traditional hyperparameter optimization methods SMBO. In our L2 norm experiments, our method yielded state-of-the-art performance, and in many cases outperformed the previous best configuration approach.
Asynch-SGBDT: Asynchronous Parallel Stochastic Gradient Boosting Decision Tree based on Parameters Server
Aug 17, 2018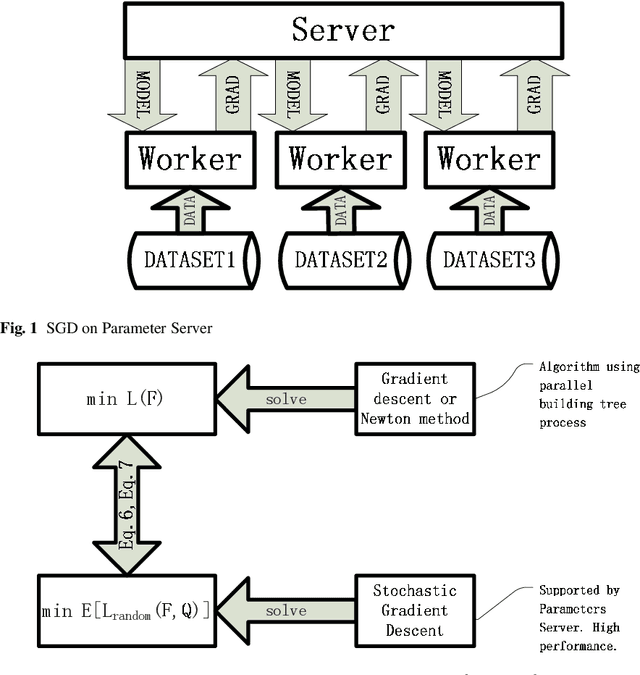

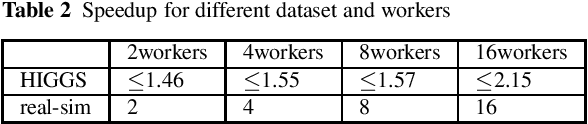
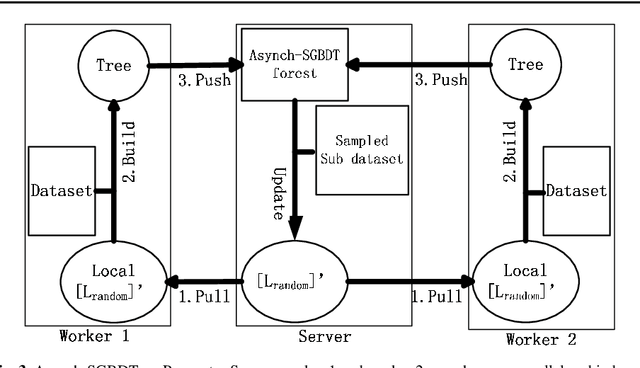
In AI research and industry, machine learning is the most widely used tool. One of the most important machine learning algorithms is Gradient Boosting Decision Tree, i.e. GBDT whose training process needs considerable computational resources and time. To shorten GBDT training time, many works tried to apply GBDT on Parameter Server. However, those GBDT algorithms are synchronous parallel algorithms which fail to make full use of Parameter Server. In this paper, we examine the possibility of using asynchronous parallel methods to train GBDT model and name this algorithm as asynch-SGBDT (asynchronous parallel stochastic gradient boosting decision tree). Our theoretical and experimental results indicate that the scalability of asynch-SGBDT is influenced by the sample diversity of datasets, sampling rate, step length and the setting of GBDT tree. Experimental results also show asynch-SGBDT training process reaches a linear speedup in asynchronous parallel manner when datasets and GBDT trees meet high scalability requirements.
Weighted parallel SGD for distributed unbalanced-workload training system
Aug 16, 2017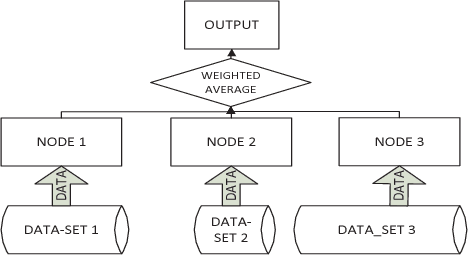
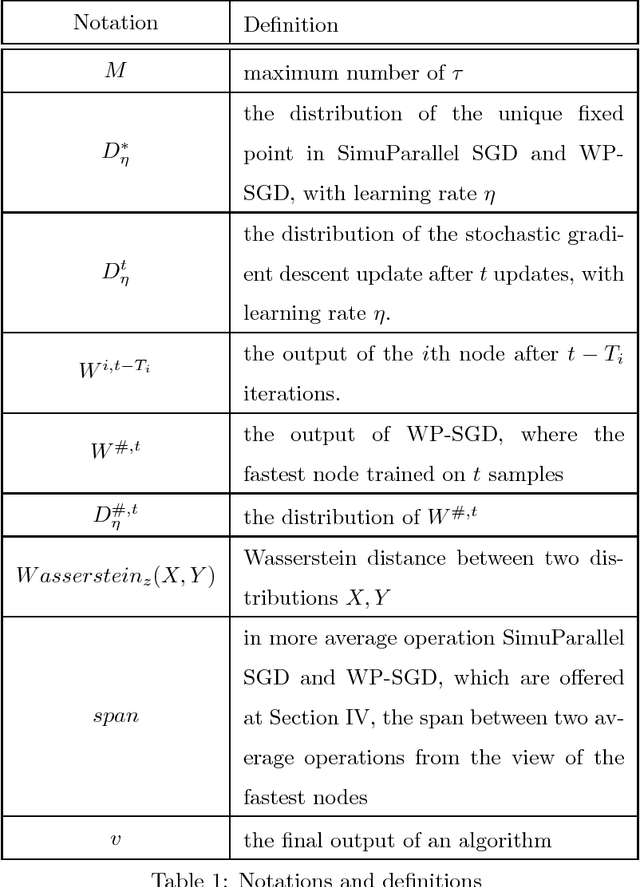
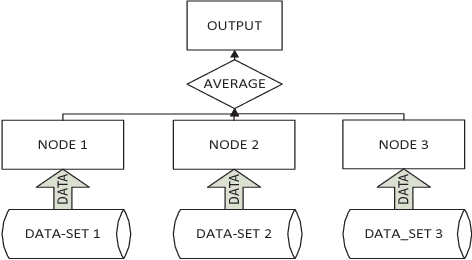
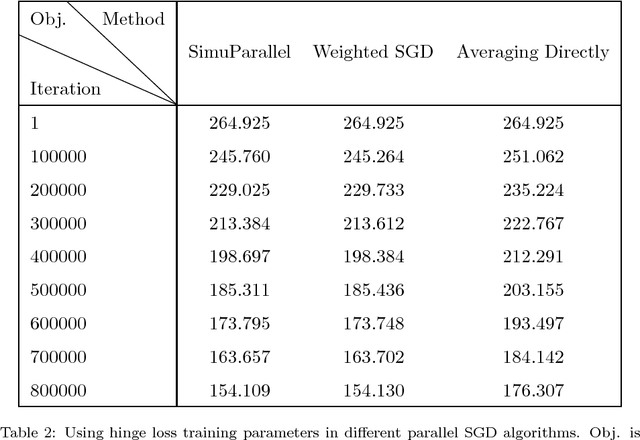
Stochastic gradient descent (SGD) is a popular stochastic optimization method in machine learning. Traditional parallel SGD algorithms, e.g., SimuParallel SGD, often require all nodes to have the same performance or to consume equal quantities of data. However, these requirements are difficult to satisfy when the parallel SGD algorithms run in a heterogeneous computing environment; low-performance nodes will exert a negative influence on the final result. In this paper, we propose an algorithm called weighted parallel SGD (WP-SGD). WP-SGD combines weighted model parameters from different nodes in the system to produce the final output. WP-SGD makes use of the reduction in standard deviation to compensate for the loss from the inconsistency in performance of nodes in the cluster, which means that WP-SGD does not require that all nodes consume equal quantities of data. We also analyze the theoretical feasibility of running two other parallel SGD algorithms combined with WP-SGD in a heterogeneous environment. The experimental results show that WP-SGD significantly outperforms the traditional parallel SGD algorithms on distributed training systems with an unbalanced workload.