 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward a Generalized Defense Across Sparse, Continuous, and Structured Parameter Attacks
Jun 03, 2026Deep neural networks are increasingly deployed across heterogeneous and partially untrusted environments, where models are distributed through cloud storage, CI/CD pipelines, containerized services, and edge execution platforms. This broad deployment landscape exposes model parameters to various integrity risks. Unlike input-space adversarial attacks, parameter attacks directly tamper with the model's internal parameters and persist across all subsequent inferences. Existing defenses either require retraining, incur significant accuracy degradation, or are limited to specific attack classes. However, in real-world deployment scenarios, the forms of parameter attacks are often unpredictable. To address this challenge, we present ParDef, a generalized defense for deep neural networks against diverse types of parameter attacks. ParDef integrates keyed channel reparameterization, which obscures sensitive parameter directions, QC-LDPC quantization, which embeds redundancy and supports error correction, and adaptive robust inference, which stabilizes predictions under uncertainty. Our evaluation on CIFAR-10, CIFAR-100, and Tiny-ImageNet using ResNet and VGG models demonstrates that ParDef consistently reduces attack success rates across different parameter attacks while maintaining high model performance and incurring only moderate deployment overhead. These results highlight that ParDef is a practical and generalized defense for DNN deployments.
Spark Policy Toolkit: Semantic Contracts and Scalable Execution for Policy Learning in Spark
Apr 27, 2026Custom policy-learning pipelines in Spark fail for two coupled systems reasons: rowwise Python execution makes inference impractical, and driver-side candidate materialization makes split search fragile at feature scale. We present Spark Policy Toolkit, a semantics-governed systems toolkit for scalable policy learning in Spark. The toolkit provides two Spark-native primitives: partition-initialized vectorized inference through mapInPandas and mapInArrow, and collect-less split search that scores candidates on executors. Both primitives are governed by one fixed-input semantic contract: the same rows, feature order, treatment vocabulary, preprocessing manifest, and split boundaries must preserve per-row score vectors, best-split decisions, and end-to-end learned policy outputs. The evaluation combines practical baseline ladders, backend parity checks, measured split-search scale results, synthetic and Hillstrom end-to-end policy preservation, missingness stress, partition and order perturbation tests, quantile-boundary sensitivity, and a concrete adversarial failure catalog. On a 40-worker Databricks cluster, mapInArrow reaches 4.72M rows/s at 10M matched rows and 7.23M rows/s at 50M rows, while collect-less split search remains valid from F = 10 through F = 1000 with 124000 candidate rows, where the driver-collect baseline is intentionally skipped. Across 24 backend-ablation settings, mapInArrow wins 18 while mapInPandas wins 6, so the paper treats backend choice as workload-dependent rather than universal. Once the fixed-input lock is enforced, all six tested repartition/coalesce/shuffle perturbations preserve identical signatures; before lock, all six drift. The central result is not speed alone: throughput and collect-less execution are the mechanisms that let policy semantics survive at Spark scale.
A Multi-Variate Triple-Regression Forecasting Algorithm for Long-Term Customized Allergy Season Prediction
May 10, 2020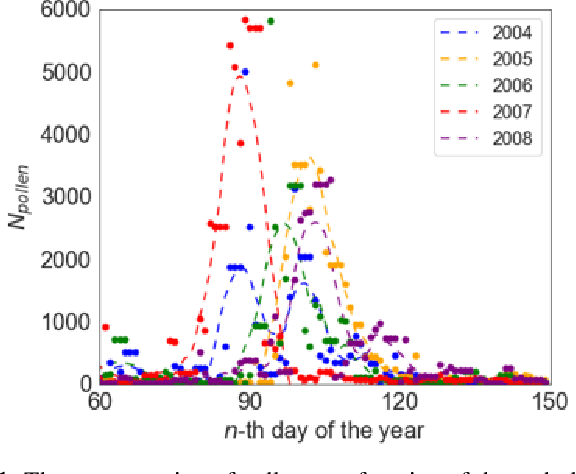
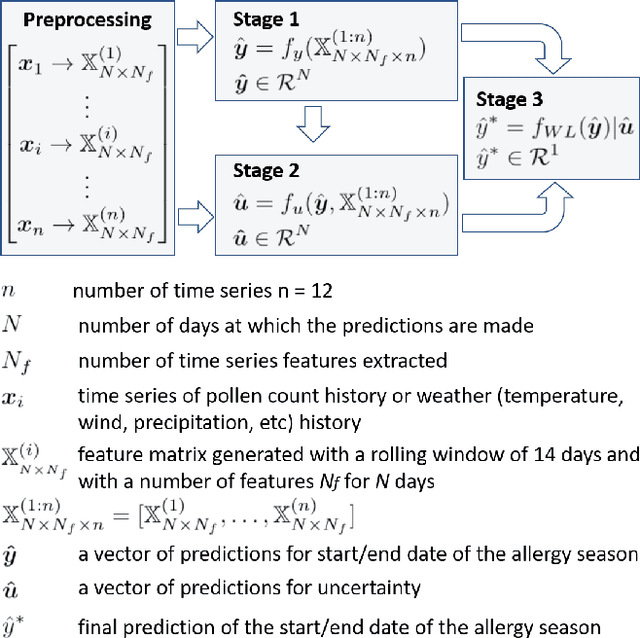
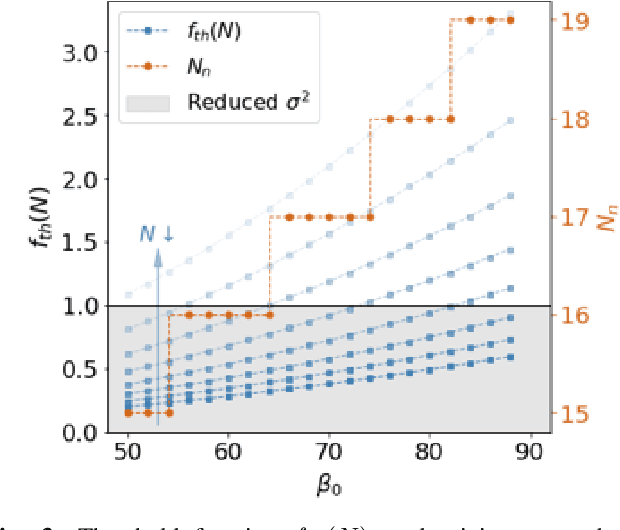
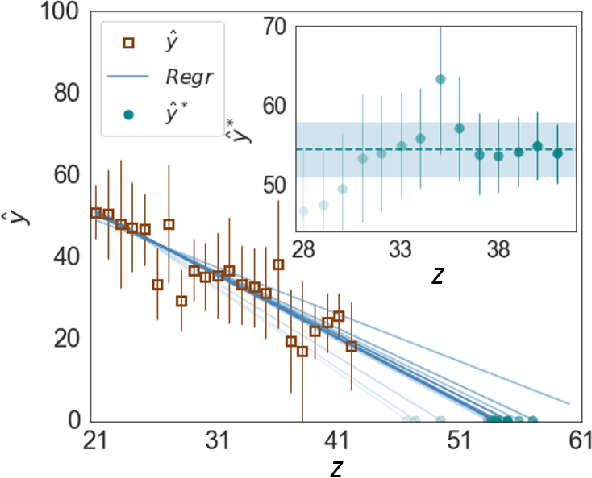
In this paper, we propose a novel multi-variate algorithm using a triple-regression methodology to predict the airborne-pollen allergy season that can be customized for each patient in the long term. To improve the prediction accuracy, we first perform a pre-processing to integrate the historical data of pollen concentration and various inferential signals from other covariates such as the meteorological data. We then propose a novel algorithm which encompasses three-stage regressions: in Stage 1, a regression model to predict the start/end date of a airborne-pollen allergy season is trained from a feature matrix extracted from 12 time series of the covariates with a rolling window; in Stage 2, a regression model to predict the corresponding uncertainty is trained based on the feature matrix and the prediction result from Stage 1; in Stage 3, a weighted linear regression model is built upon prediction results from Stage 1 and 2. It is observed and proved that Stage 3 contributes to the improved forecasting accuracy and the reduced uncertainty of the multi-variate triple-regression algorithm. Based on different allergy sensitivity level, the triggering concentration of the pollen - the definition of the allergy season can be customized individually. In our backtesting, a mean absolute error (MAE) of 4.7 days was achieved using the algorithm. We conclude that this algorithm could be applicable in both generic and long-term forecasting problems.
Mental Task Classification Using Electroencephalogram Signal
Oct 02, 2019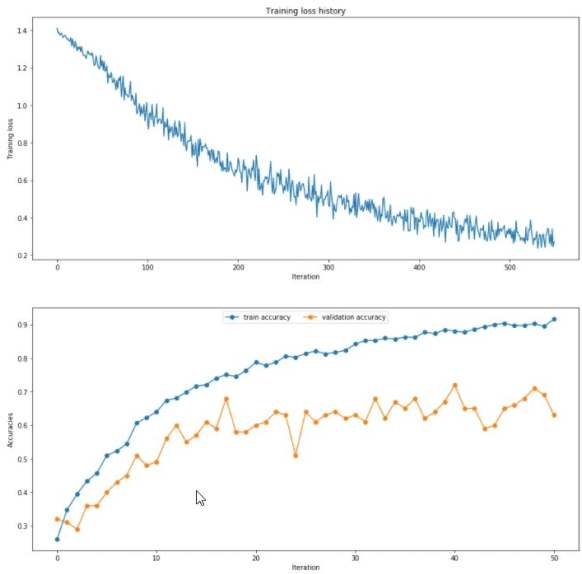
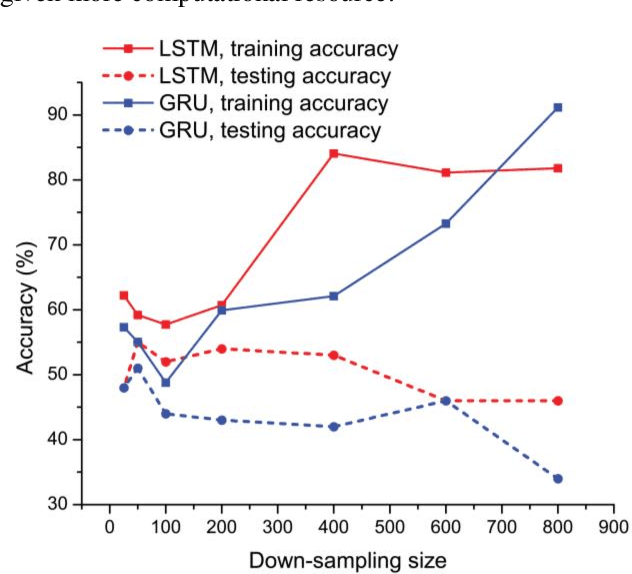
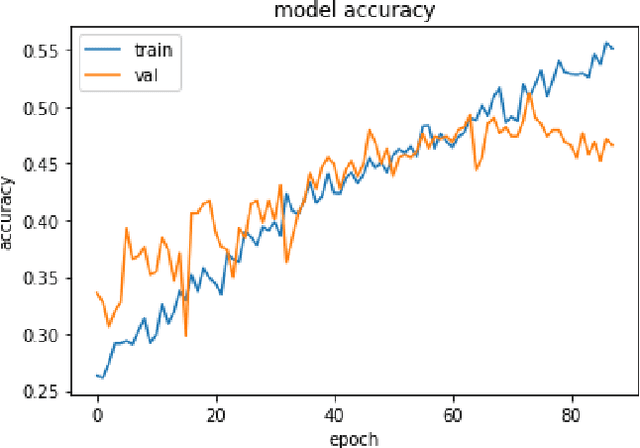
This paper studies the classification problem on electroencephalogram (EEG) data of mental tasks, using standard architecture of three-layer CNN, stacked LSTM, stacked GRU. We further propose a novel classifier - a mixed LSTM model with a CNN decoder. A hyperparameter optimization on CNN shows validation accuracy of 72% and testing accuracy of 62%. The stacked LSTM and GRU models with FFT preprocessing and downsampling on data achieve 55% and 51% testing accuracy respectively. As for the mixed LSTM model with CNN decoder, validation accuracy of 75% and testing accuracy of 70% are obtained. We believe the mixed model is more robust and accurate than both CNN and LSTM individually, by using the CNN layer as a decoder for following LSTM layers. The code is completed in the framework of Pytorch and Keras. Results and code can be found at https://github.com/theyou21/BigProject.