 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCanonical Correlation Patterns for Validating Clustering of Multivariate Time Series
Jul 22, 2025Clustering of multivariate time series using correlation-based methods reveals regime changes in relationships between variables across health, finance, and industrial applications. However, validating whether discovered clusters represent distinct relationships rather than arbitrary groupings remains a fundamental challenge. Existing clustering validity indices were developed for Euclidean data, and their effectiveness for correlation patterns has not been systematically evaluated. Unlike Euclidean clustering, where geometric shapes provide discrete reference targets, correlations exist in continuous space without equivalent reference patterns. We address this validation gap by introducing canonical correlation patterns as mathematically defined validation targets that discretise the infinite correlation space into finite, interpretable reference patterns. Using synthetic datasets with perfect ground truth across controlled conditions, we demonstrate that canonical patterns provide reliable validation targets, with L1 norm for mapping and L5 norm for silhouette width criterion and Davies-Bouldin index showing superior performance. These methods are robust to distribution shifts and appropriately detect correlation structure degradation, enabling practical implementation guidelines. This work establishes a methodological foundation for rigorous correlation-based clustering validation in high-stakes domains.
CSTS: A Benchmark for the Discovery of Correlation Structures in Time Series Clustering
May 20, 2025Time series clustering promises to uncover hidden structural patterns in data with applications across healthcare, finance, industrial systems, and other critical domains. However, without validated ground truth information, researchers cannot objectively assess clustering quality or determine whether poor results stem from absent structures in the data, algorithmic limitations, or inappropriate validation methods, raising the question whether clustering is "more art than science" (Guyon et al., 2009). To address these challenges, we introduce CSTS (Correlation Structures in Time Series), a synthetic benchmark for evaluating the discovery of correlation structures in multivariate time series data. CSTS provides a clean benchmark that enables researchers to isolate and identify specific causes of clustering failures by differentiating between correlation structure deterioration and limitations of clustering algorithms and validation methods. Our contributions are: (1) a comprehensive benchmark for correlation structure discovery with distinct correlation structures, systematically varied data conditions, established performance thresholds, and recommended evaluation protocols; (2) empirical validation of correlation structure preservation showing moderate distortion from downsampling and minimal effects from distribution shifts and sparsification; and (3) an extensible data generation framework enabling structure-first clustering evaluation. A case study demonstrates CSTS's practical utility by identifying an algorithm's previously undocumented sensitivity to non-normal distributions, illustrating how the benchmark enables precise diagnosis of methodological limitations. CSTS advances rigorous evaluation standards for correlation-based time series clustering.
Understandable Controller Extraction from Video Observations of Swarms
Sep 02, 2022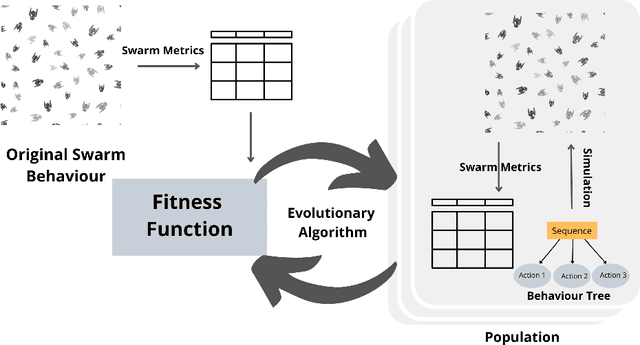
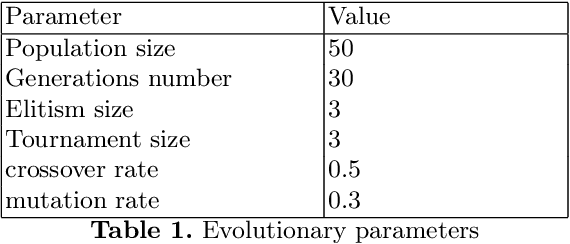
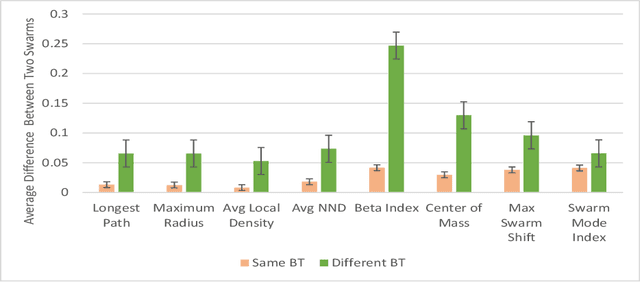

Swarm behavior emerges from the local interaction of agents and their environment often encoded as simple rules. Extracting the rules by watching a video of the overall swarm behavior could help us study and control swarm behavior in nature, or artificial swarms that have been designed by external actors. It could also serve as a new source of inspiration for swarm robotics. Yet extracting such rules is challenging as there is often no visible link between the emergent properties of the swarm and their local interactions. To this end, we develop a method to automatically extract understandable swarm controllers from video demonstrations. The method uses evolutionary algorithms driven by a fitness function that compares eight high-level swarm metrics. The method is able to extract many controllers (behavior trees) in a simple collective movement task. We then provide a qualitative analysis of behaviors that resulted in different trees, but similar behaviors. This provides the first steps toward automatic extraction of swarm controllers based on observations.