 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevelopment of a hybrid machine-learning and optimization tool for performance-based solar shading design
Jan 09, 2022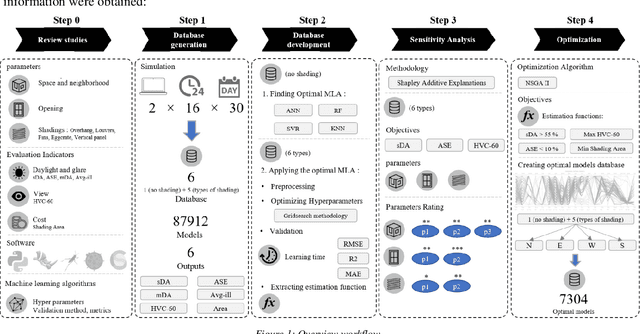
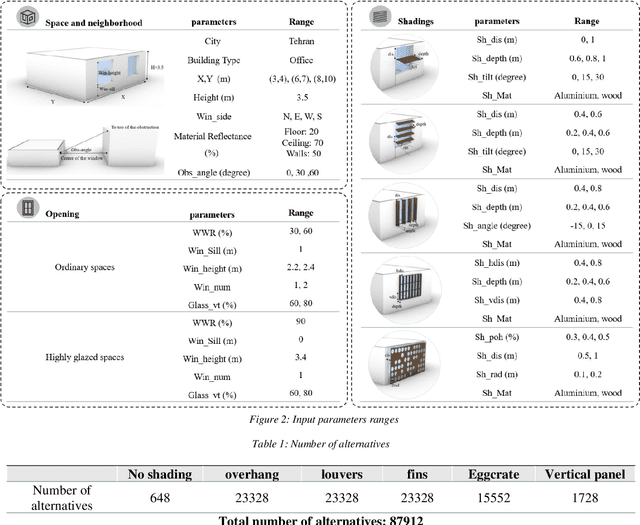
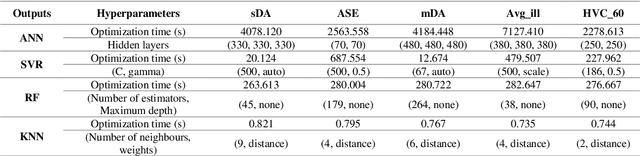
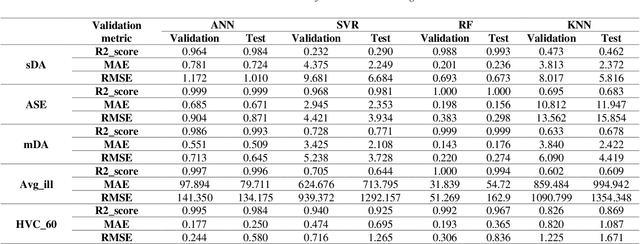
Solar shading design should be done for the desired Indoor Environmental Quality (IEQ) in the early design stages. This field can be very challenging and time-consuming also requires experts, sophisticated software, and a large amount of money. The primary purpose of this research is to design a simple tool to study various models of solar shadings and make decisions easier and faster in the early stages. Database generation methods, artificial intelligence, and optimization have been used to achieve this goal. This tool includes two main parts of 1. predicting the performance of the user-selected model along with proposing effective parameters and 2. proposing optimal pre-prepared models to the user. In this regard, initially, a side-lit shoebox model with variable parameters was modeled parametrically, and five common solar shading models with their variables were applied to the space. For each solar shadings and the state without shading, metrics related to daylight and glare, view, and initial costs were simulated. The database generated in this research includes 87912 alternatives and six calculated metrics introduced to optimized machine learning models, including neural network, random Forrest, support vector regression, and k nearest neighbor. According to the results, the most accurate and fastest estimation model was Random Forrest, with an r2_score of 0.967 to 1. Then, sensitivity analysis was performed to identify the most influential parameters for each shading model and the state without it. This analysis distinguished the most effective parameters, including window orientation, WWR, room width, length, and shading depth. Finally, by optimizing the estimation function of machine learning models with the NSGA II algorithm, about 7300 optimal models were identified. The developed tool can evaluate various design alternatives in less than a few seconds for each.
A Machine-learning Framework for Acoustic Design Assessment in Early Design Stages
Sep 14, 2021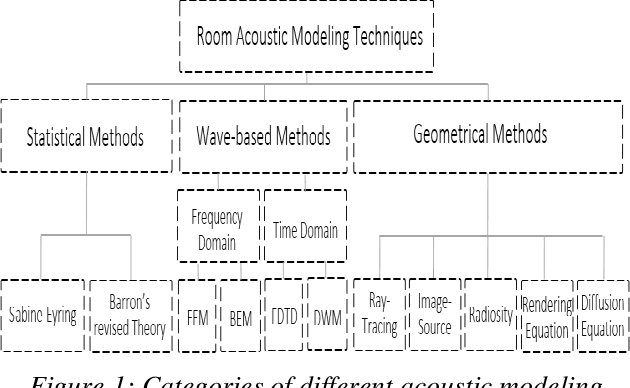
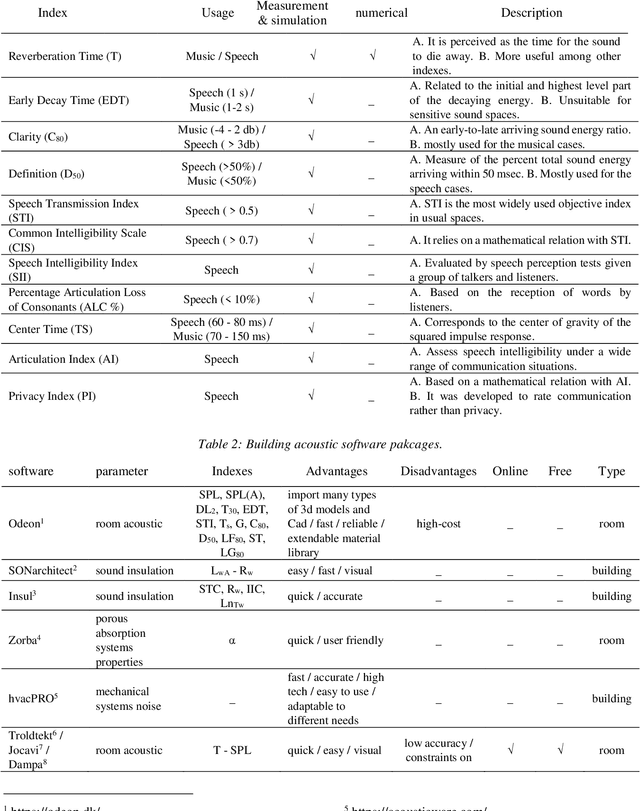
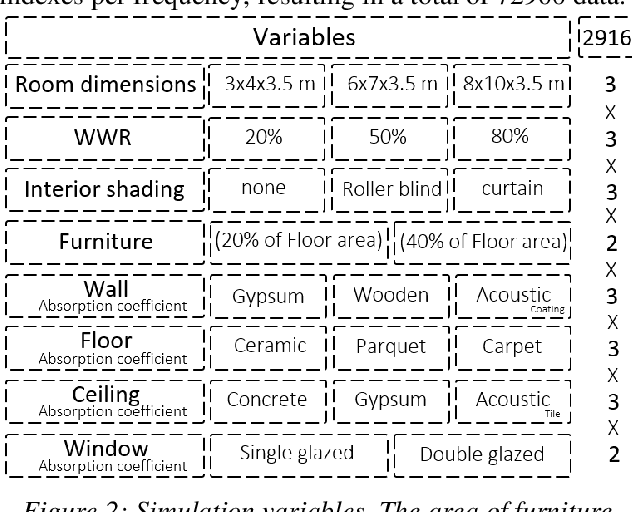
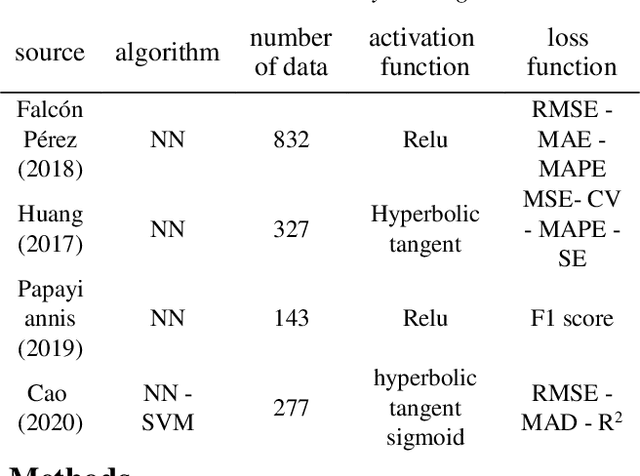
In time-cost scale model studies, predicting acoustic performance by using simulation methods is a commonly used method that is preferred. In this field, building acoustic simulation tools are complicated by several challenges, including the high cost of acoustic tools, the need for acoustic expertise, and the time-consuming process of acoustic simulation. The goal of this project is to introduce a simple model with a short calculation time to estimate the room acoustic condition in the early design stages of the building. This paper presents a working prototype for a new method of machine learning (ML) to approximate a series of typical room acoustic parameters using only geometric data as input characteristics. A novel dataset consisting of acoustical simulations of a single room with 2916 different configurations are used to train and test the proposed model. In the stimulation process, features that include room dimensions, window size, material absorption coefficient, furniture, and shading type have been analysed by using Pachyderm acoustic software. The mentioned dataset is used as the input of seven machine-learning models based on fully connected Deep Neural Networks (DNN). The average error of ML models is between 1% to 3%, and the average error of the new predicted samples after the validation process is between 2% to 12%.
A machine-learning framework for daylight and visual comfort assessment in early design stages
Sep 14, 2021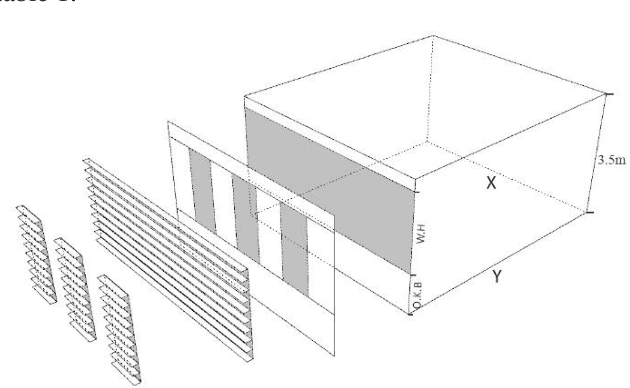
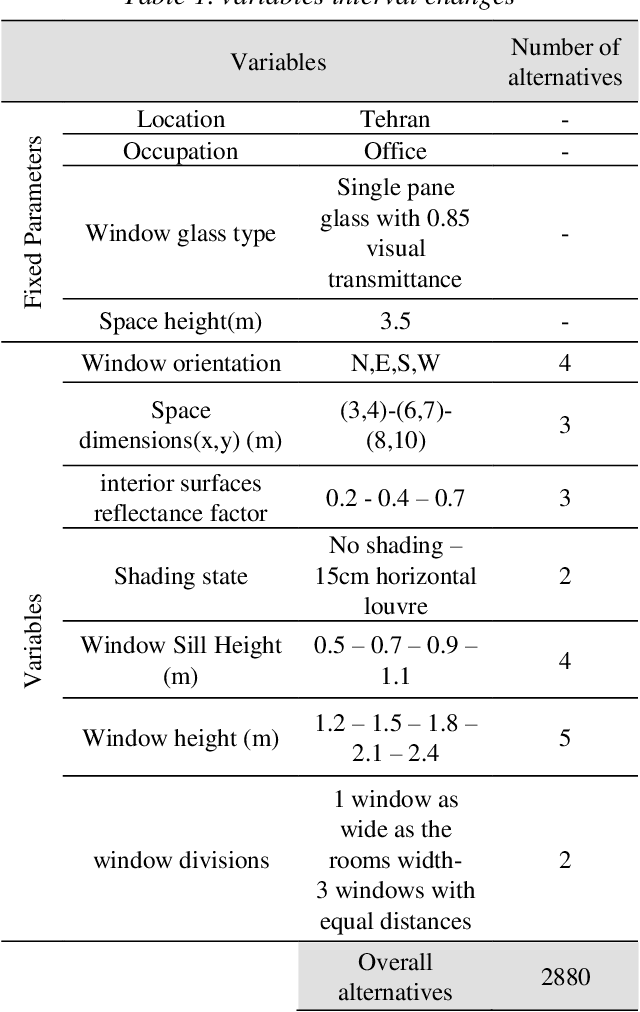
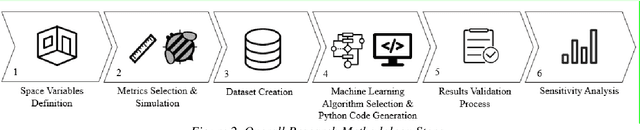

This research is mainly focused on the assessment of machine learning algorithms in the prediction of daylight and visual comfort metrics in the early design stages. A dataset was primarily developed from 2880 simulations derived from Honeybee for Grasshopper. The simulations were done for a shoebox space with a one side window. The alternatives emerged from different physical features, including room dimensions, interior surfaces reflectance, window dimensions and orientations, number of windows, and shading states. 5 metrics were used for daylight evaluations, including UDI, sDA, mDA, ASE, and sVD. Quality Views were analyzed for the same shoebox spaces via a grasshopper-based algorithm, developed from the LEED v4 evaluation framework for Quality Views. The dataset was further analyzed with an Artificial Neural Network algorithm written in Python. The accuracy of the predictions was estimated at 97% on average. The developed model could be used in early design stages analyses without the need for time-consuming simulations in previously used platforms and programs.