 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Natural Language Processing For Public Health Screening On YouTube: A COVID-19 Case Study
Jun 01, 2023



Background: Social media platforms have become a viable source of medical information, with patients and healthcare professionals using them to share health-related information and track diseases. Similarly, YouTube, the largest video-sharing platform in the world contains vlogs where individuals talk about their illnesses. The aim of our study was to investigate the use of Natural Language Processing (NLP) to identify the spoken content of YouTube vlogs related to the diagnosis of Coronavirus disease of 2019 (COVID-19) for public health screening. Methods: COVID-19 videos on YouTube were searched using relevant keywords. A total of 1000 videos being spoken in English were downloaded out of which 791 were classified as vlogs, 192 were non-vlogs, and 17 were deleted by the channel. The videos were converted into a textual format using Microsoft Streams. The textual data was preprocessed using basic and advanced preprocessing methods. A lexicon of 200 words was created which contained words related to COVID-19. The data was analyzed using topic modeling, word clouds, and lexicon matching. Results: The word cloud results revealed discussions about COVID-19 symptoms like "fever", along with generic terms such as "mask" and "isolation". Lexical analysis demonstrated that in 96.46% of videos, patients discussed generic terms, and in 95.45% of videos, people talked about COVID-19 symptoms. LDA Topic Modeling results also generated topics that successfully captured key themes and content related to our investigation of COVID-19 diagnoses in YouTube vlogs. Conclusion: By leveraging NLP techniques on YouTube vlogs public health practitioners can enhance their ability to mitigate the effects of pandemics and effectively respond to public health challenges.
Classification of Vocal Bursts for ACII 2022 A-VB-Type Competition using Convolutional Network Networks and Deep Acoustic Embeddings
Sep 29, 2022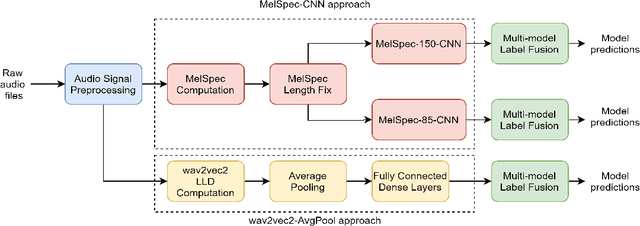
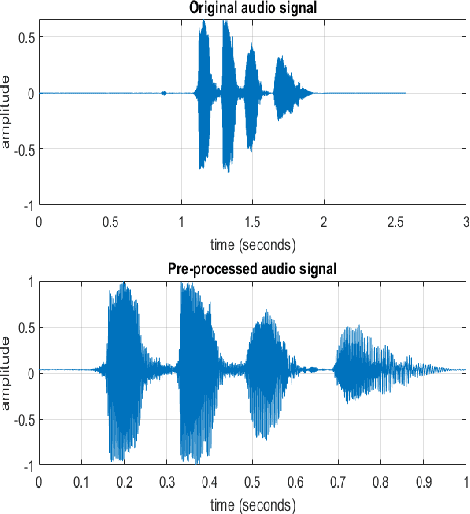
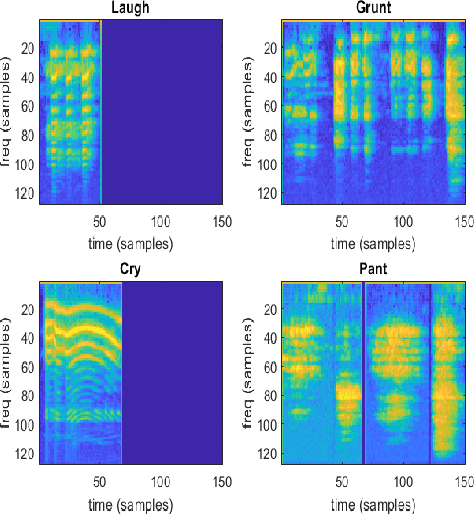
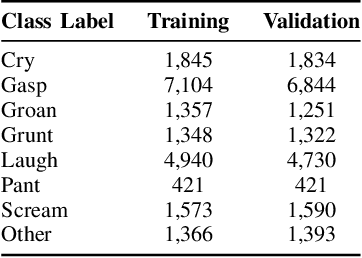
This report provides a brief description of our proposed solution for the Vocal Burst Type classification task of the ACII 2022 Affective Vocal Bursts (A-VB) Competition. We experimented with two approaches as part of our solution for the task at hand. The first of which is based on convolutional neural networks trained on Mel Spectrograms, and the second is based on average pooling of deep acoustic embeddings from a pretrained wav2vec2 model. Our best performing model achieves an unweighted average recall (UAR) of 0.5190 for the test partition, compared to the chance-level UAR of 0.1250 and a baseline of 0.4172. Thus, an improvement of around 20% over the challenge baseline. The results reported in this document demonstrate the efficacy of our proposed approaches to solve the AV-B Type Classification task.